

Road to Shipping PeerDAS to Mainnet in 2025
Just dropping some thoughts on what it might take to ship PeerDAS this year and how we might align soon on scope and timelines.
The current PeerDAS implementation has gone through a long development cycle and multiple spec iterations. It's not perfect (and never will be), but that's fine - it's not the final form of blob scaling. We're likely to keep evolving it after Fusaka anyway.
We've reached a point where further improvements are starting to compete with the value of just shipping what we have. Without drawing a line, we risk turning this into technical debt - or worse, wasted work.
With Pectra successfully shipped, focus has shifted to Fusaka, and PeerDAS testing is ramping up. As testing ramps up and more people get involved, it opens the door to more ideas and more temptation to keep changing the spec.
While the new ideas are exciting, I think it's time we start seriously scoping and freezing the spec. If we want to launch this year - which I'd personally really like to, given how long PeerDAS has been in the works - we need to align now on scope and planning, even if it's not 'perfect'.
Three key questions
To move forward, we should try to answer the following as soon as possible:
- Can we freeze the spec today? If not, what's missing?
- How much scaling can we safely ship in Fusaka and subsequent BPO forks? Even if it's below PeerDAS's theoretical limit (72 blobs), it still delivers value.
- What must be done before shipping this version? What improvements can wait until after the fork or the next fork?
If we can align on those, we can set a confident timeline for Fusaka, and focus purely on getting PeerDAS ready - not more rounds of design.
Improvement proposals
There are a lot of great improvements being discussed. I'm probably missing some, but here are a few categories and how they might fit:
libp2pimprovements: Lower latency, lower bandwidth. Great for high-blob-count future, but can come post-Fusaka. We can even schedule BPOs to increase blob count as networking improves.- Partial
getBlobsV2responses: Useful and likely necessary for full DAS, but do we need an interim version, or should we just go all-in on full DAS later? We need to look at the added complexity and weigh in with the benefits. It's also possible to introduce the flag after the fork. Changing the default behaviour now would likely require a spec change, implementation and testing cycle - an effort that often gets underestimated. - SSZ support in Engine APIs: makes sense performance-wise, but maybe not Fusaka-critical.
- And many others...
These are worth planning for upcoming forks, but unless one of them turns out to be a clear blocker, they shouldn't hold up Fusaka.
Our take
For Lighthouse, once validator custody backfilling is done, we're mainly focused on:
- Sync performance and resilience
- Identifying and fixing performance bottlenecks (e.g. gossip verification)
- Bug-fixing and testing cycles
I can't speak for the ELs, but suspect it's probably similar across other CL clients.
Sunnyside Labs' testing showed network destabilisation at around 72 blobs, which is super helpful. Looking a bit deeper into the metrics, Lighthouse isn't actually performant at that level - I put together a quick analysis based on their metrics in the Appendix section below.
Rather than spending time trying to push to 72 blobs, I think we'd be better off setting a more realistic number that already works today, with some headroom, as the target and making it robust. That gives us a much better shot at shipping PeerDAS this year. It still delivers real benefits and feels much more achievable.
Here are the current thoughts from the Lighthouse team:
- Spec freeze: Yes, unless any critical issues are found
- Tentative target scale: Launch Fusaka with up to 18 blobs (2x Pectra), and schedule one BPO fork to increase this to 24 blobs. Observe on Mainnet and consider further BPO forks once we have real data.
- Mainnet readiness: All major clients are stable with private blobs + MEV flow, proven recovery from non-finality, and sufficient sync performance.
If we can freeze the spec (including the blob schedule) soon, teams can focus fully on getting the current implementation production-ready.
Planning
Here's a rough timeline to work backwards from a mid-October 2025 mainnet launch:
- Mid October - Mainnet fork
- Mid August - Begin public testnets
- Mid July
- Private blobs + MEV flow testing
- Non-finality testing
- Early July (maybe next ACD?)
- Launch
fusaka-devnet-2 - Decide on spec freeze
- Decide whether to have a tentative blob schedule:
- Choose a max blob count for testing and production target - ideally something that works today, so we can focus on sync and edge cases
- Define a blob schedule leading to that max blob count and stick to it
IMO this may look quite tight with the way things are progressing now, but I feel like it's not unrealistic if we can align quickly and stay focused on the Fusaka scope.
Conclusion
The main point I want to get across is this: if we believe shipping PeerDAS this year is crucial, we really need to focus on hardening the current implementation. That means tightening the scope and freezing the spec as soon as possible.
Remember, even small changes create distraction and introduce delays - from spec updates to extra testing cycles - and we often underestimate the time and effort involved. IMO, we should focus on productionising the clients from this point on.
Finalising a blob schedule without enough real-world data might be a bit risky, but having a tentative target to focus testing around would still be very helpful. The main thing now is trying to answer the three key questions above, and making sure we align quickly.
Thanks to everyone for reviewing and sharing valuable feedback while I was putting this together - especially Pawan, Francesco, and the rest of the Lighthouse team, and the Sunnyside Labs team for the devnet work. Let me know if I'm missing anything - keen to hear thoughts and get a sense of the feasibility of the timeline.
Appendix
This section is a quick analysis of the recent test report from Sunnyside Lab on the Devnet-1-Mixed devnet, which includes a mix of clients and a max blob count of 128.
The network appears to hold up until around 72 blobs. However, looking a bit deeper, the metric beacon_block_delay_attestable_slot_start exceeds 4 seconds for supernodes around 2025-06-13 23:16:00:
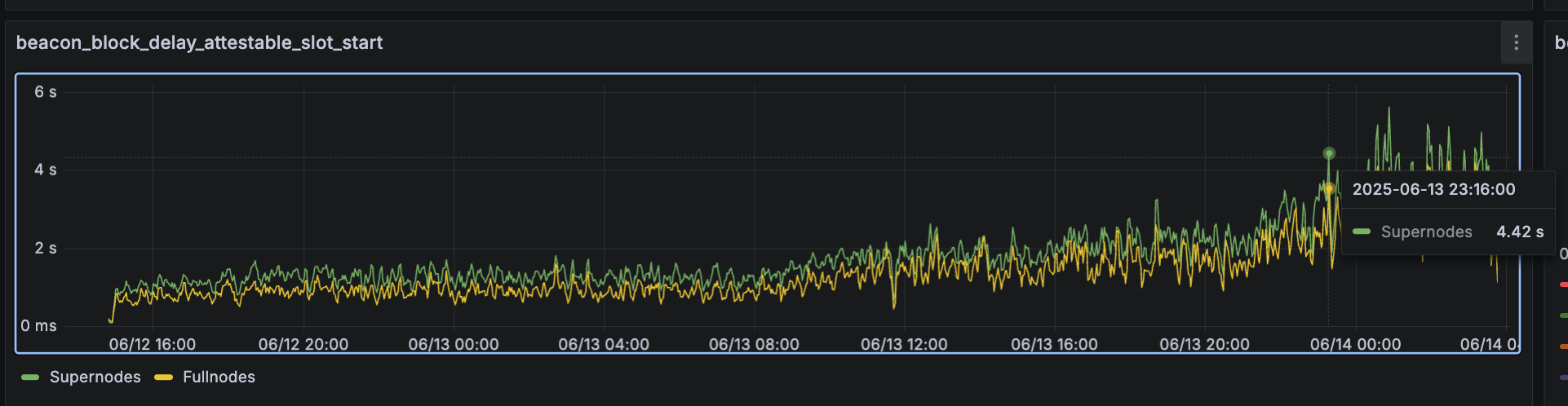
At that point, blob count is around 70. While the network hasn't fallen apart, this suggests that consensus performance may already be degrading - so there's likely substaintial work required to safely scale to 70 blobs.
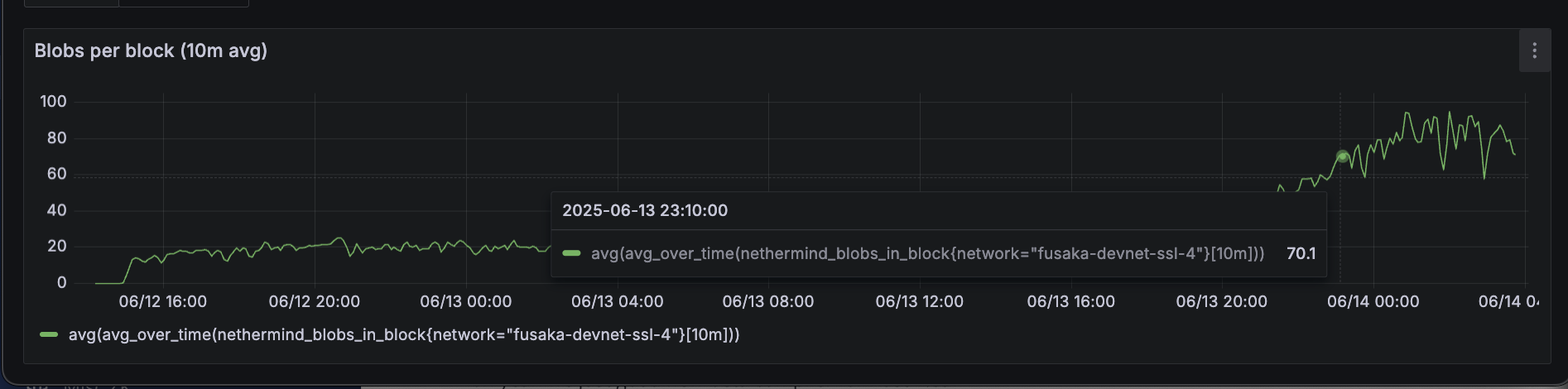
What blob count should we target?
Based on the above, 72 blobs seems too high to target right now. The beacon_block_delay_attestable_slot_start metric is key, since if it exceeds 4 seconds, nodes would not attest to the block.
On Mainnet, this delayis typically around 2-3 seconds. It would be useful to identify at what blob count the delay begins to exceed that threshold.
On this devnet, the trend holds until around 2025-06-13 18:30, after which we start seeing some supernodes averaging above 3 seconds:
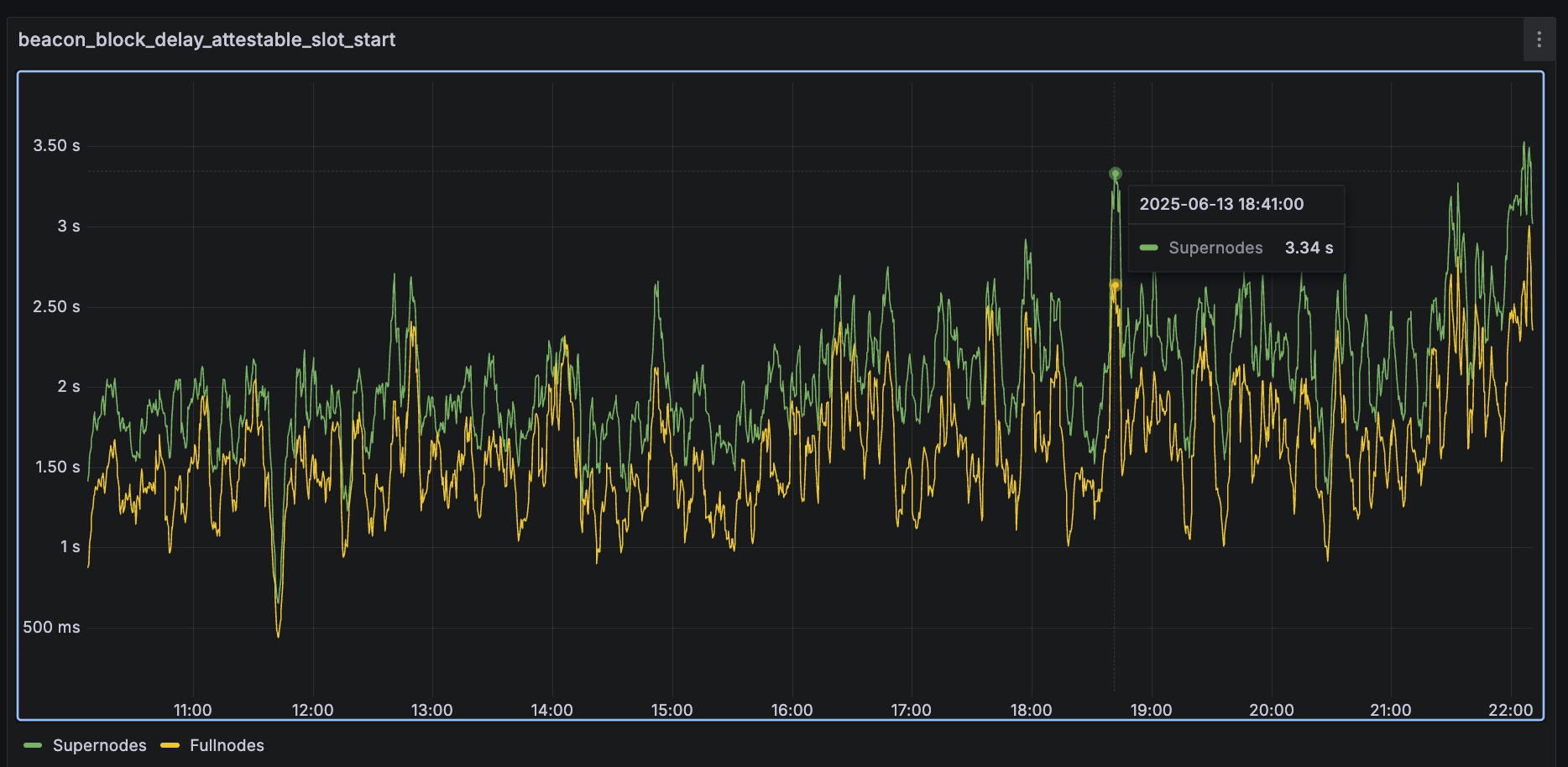
At that point, blocks are reaching around 50 blobs:
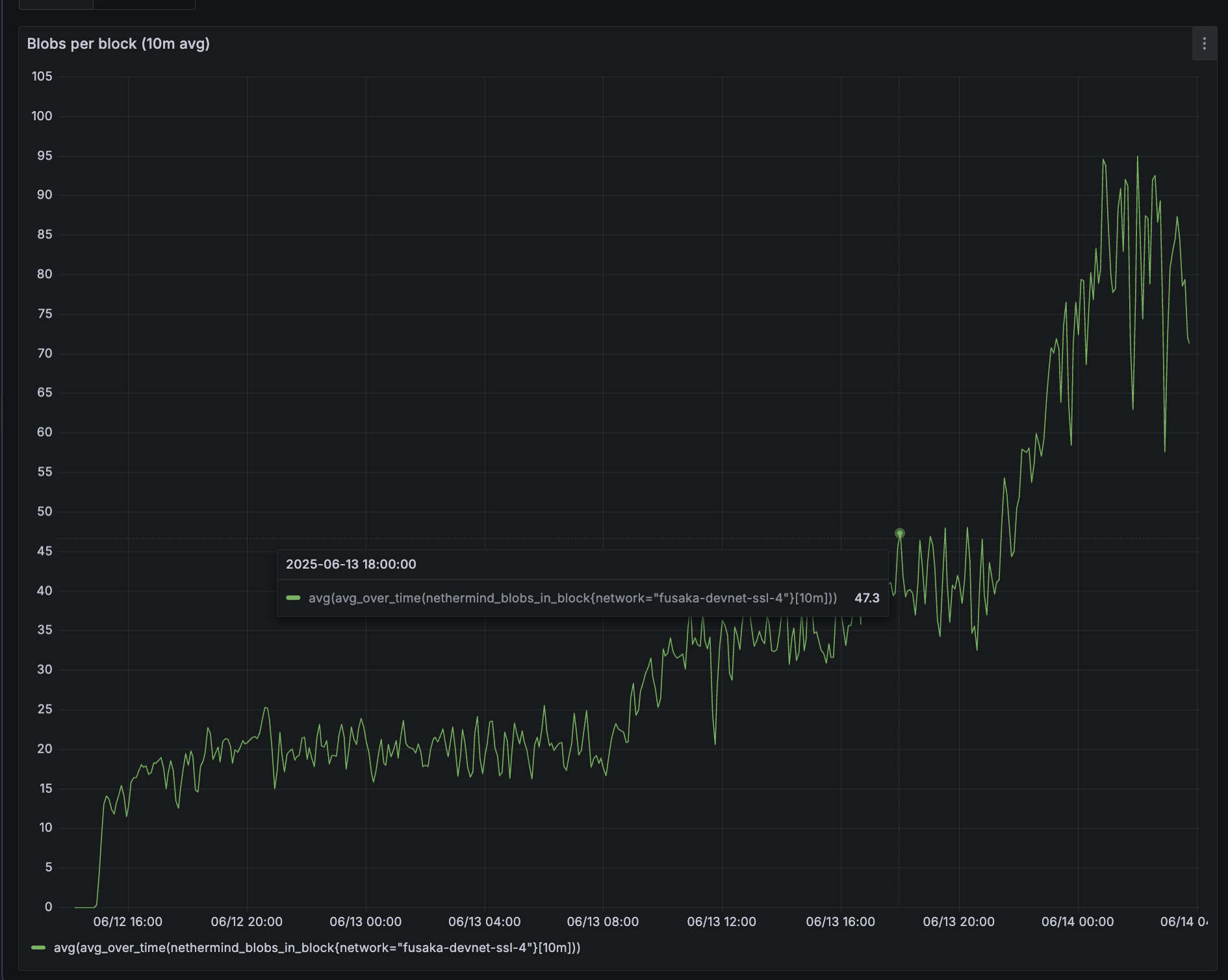
This is of course a very rough estimate and based on a small devnet. But for now, targetting something below 50 (with enough headroom in the Fusaka BPO forks) feels like a more realistic and safer approach.