


Intro
As we move forward with Ethereum's rollup-centric roadmap to scaling, we're seeing more L2s appear and a few of them moving to a more mature state (with fault proofs, better wallet UX etc.), and now more users transacting on L2s. Blob transactions (EIP-4844), introduced in the Dencun upgrade in March 2024, have lowered transaction costs on L2s. As usage increases, further L1 scaling is needed to maintain low data gas prices. The screenshot below shows comparable figures on L2 rollup activities over time, compared to Ethereum Mainnet (L1).
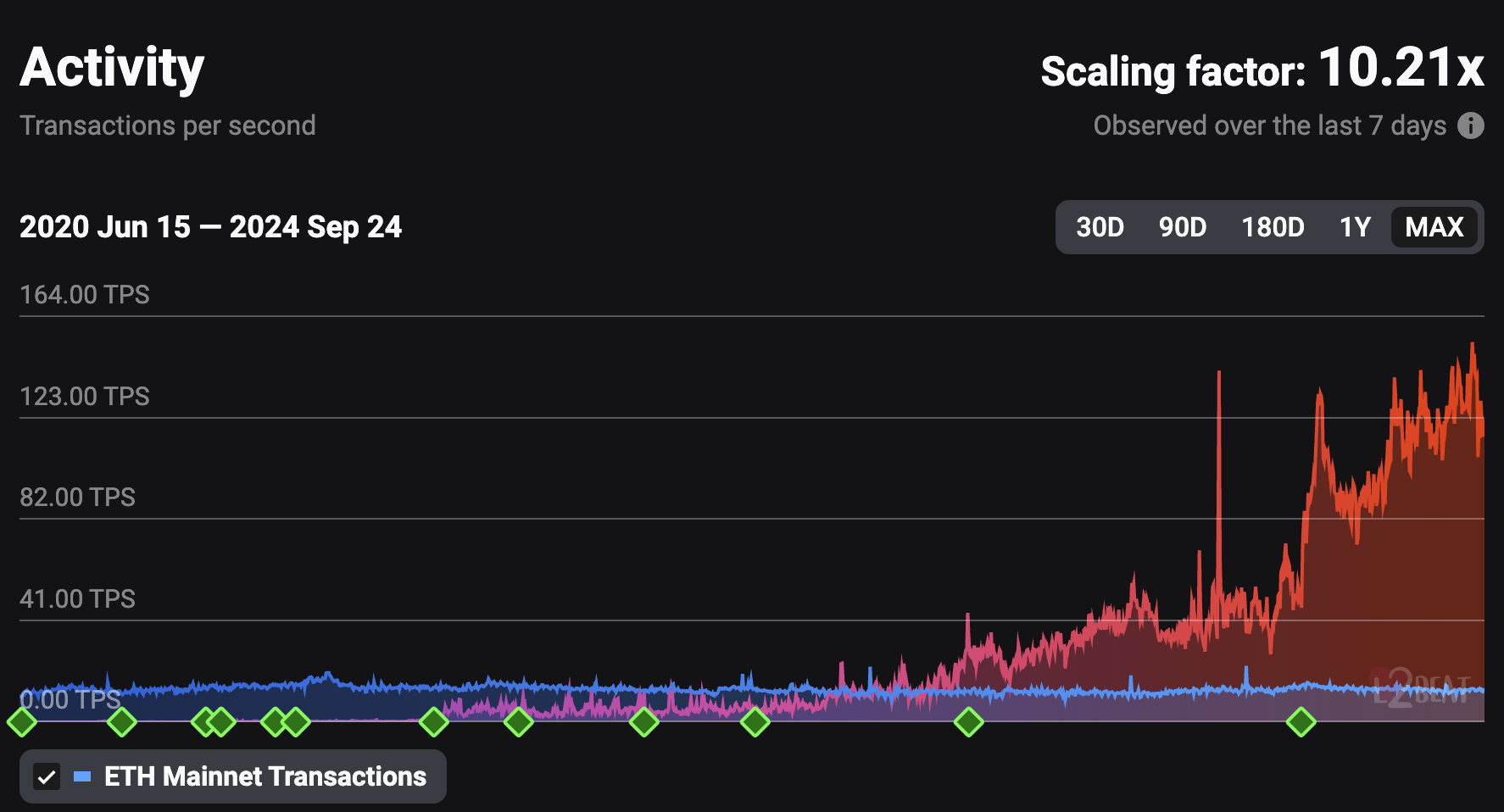 source: https://l2beat.com/scaling/activity
source: https://l2beat.com/scaling/activity
The next Ethereum upgrade (Pectra) is expected to increase the maximum blob count beyond 6 per block. While this can be done by demanding more powerful hardware and better bandwidth, it risks compromising decentralisation by pushing away home stakers who can't afford further investment. Our goal is to ensure that current validators, including those using consumer-grade hardware, can continue operating smoothly after these upgrades.
The solution to this is Data Availability Sampling (DAS), which enables the network to verify data availability without placing excessive strain on individual nodes. Each full node downloads and verifies a small, randomly selected portion of the data, providing a high degree of certainty that the full dataset is available.
Over the past few months, client teams have been working on PeerDAS (EIP-7594), the first iteration of DAS. We've made significant progress so far, and are now tackling challenges around computation time and bandwidth for block proposers, which we aim to solve before increasing the maximum blob count and shipping to mainnet.
The following two sections describe the challenges, optimisations and assume familiarity with EIP-4844. If you're primarily interested in metrics and the impact on node operators, feel free to skip ahead to the later sections on Metrics, or Impact on Node Operators.
Outline
- Challenges and Bottlenecks
- Solutions and Possible Optimisations
- Test Setup
- Metrics
- Impact on Node Operators
- Future Work and Optimisations
- Conclusion
Challenges and Bottlenecks
Even though the current design of PeerDAS is able to reduce the bandwidth requirements for most of the time that a node is running, during block proposals, the proposer must perform intensive computation (KZG cell proofs) and distribute the erasure-coded blobs and proofs across the network as soon as possible, before the attestation deadline (4 seconds into the slot). Otherwise, they will likely miss the block or have their block re-orged out. This section explains these bottlenecks.
Proof Computation
On a MacBook Pro with an M1 Pro CPU, computing the KZG proofs for a single blob takes around 200 ms. This computation is highly parallelisable at the blob level. For instance, with 4 logical cores available, the proofs for 4 blobs can be computed in the same 200 ms. This works well for a small number of blobs, but as we scale to 16 blobs, computation on 4 logical cores could take 200 * 16 / 4 = 800 ms. However, since the node is rarely idle, it’s likely to take 1 second or more.
Bandwidth Bottleneck
With 16 blobs in a block, the amount of data the proposer would have to send could be up to 32MB (assuming all 16 blobs are utilised, and we have a healthy peer count). For average consumer broadband, this could take 2-5 seconds, meaning they are likely to miss the block proposal.
128KB * 2 * 16 * 8 = ~32MB
- 128 KB blobs
- Erasure coding extends the original data by 2x
- 16 blobs
- Gossip amplification factor: 3-8x (data is sent to multiple mesh peers in each topic)
Solutions and Possible Optimisations
Several proposed solutions aim to address the above issues: 1. Nodes to fetch blobs from execution layer (EL) mempool and make the block available without waiting for blobs to arrive over the CL p2p gossip network. 2. High capacity nodes to compute cell proofs for blobs retrieved from the EL, and broadcast them, so they propagate to the network sooner. This technique is also known as distributed blob building. 3. Pre-compute the blob proofs as they enter the EL mempool.
These solutions complement each other. We have implemented optimisations (1) and (2) in Lighthouse, and we'll focus on sharing our findings in this post. Our implementation can be found here:
Fetch Blobs from the Execution Layer (EL)
Blob latency has been an issue observed on Mainnet, as shown in the chart below (running latest Lighthouse v5.3.0), where block and blob arrival times frequently show blob delays spiking above 3 seconds. These late propagations are likely to result in blocks being missed or orphaned.
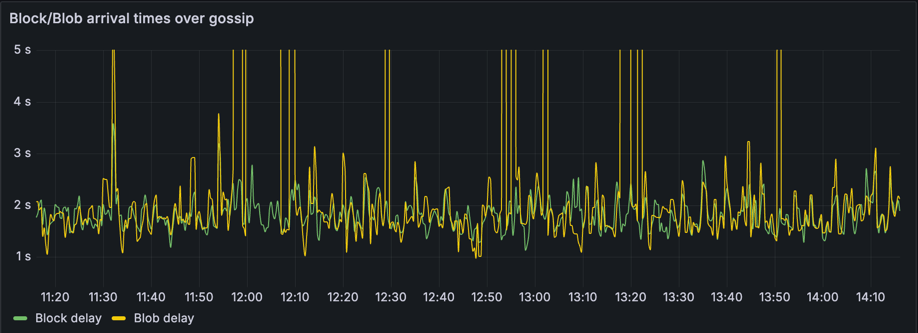
To address this, we introduced an optimisation to fetch blobs via JSON-RPC from the Execution Layer (EL). If a blob has already been seen in the public mempool, waiting for it to arrive via P2P gossip becomes unnecessary. This optimisation uses a new JSON-RPC method (engine_getBlobsV1), which allows the consensus client (CL) to quickly retrieve blobs from the EL's blob pool.
This technique is also applicable in PeerDAS, where nodes can consider a block available and attest to it without waiting for all data columns* to arrive over P2P gossip. The result is reduced block import latency and a lower likelihood of missed blocks due to blob propagation delays.
*Note: In PeerDAS, each blob is erasure-coded for redundancy and recoverability, and broken down into smaller pieces (cells or data columns) for sampling and distribution.
However, this approach does not cover blob transactions from private mempools. Block builders that include private blob transactions must ensure that blobs and proofs are computed and broadcast in time.
Distributed Blob Building
This optimisation aims to solve both computation and bandwidth bottlenecks for block proposers, by distributing the proof computation and propagation workload to more nodes - particularly more powerful nodes with higher bandwidth. In the PeerDAS case, these are typically the supernodes responsible for custodying and sampling all data columns (via the experimental Lighthouse BN flag --subscribe-all-data-column-subnets).
These supernodes can retrieve the blobs from the EL, either before the slot start (pre-computation) or after receiving the block from a peer (see Optimisation (1)). This means it's crucial for blocks to propagate quickly, which can be optimised by either: 1. Publishing the block first while computing blob proofs simultaneously. 2. Introducing a new gossip topic for block headers, which are usually much smaller than blocks, allowing block headers with KZG commitments to propagate faster (proposed by Dankrad in this post).
Once the supernodes have the blobs, they can compute the proofs and broadcast them to the network on behalf of the proposer. With better hardware and bandwidth, supernodes can generally perform this task more efficiently. Metrics will be shared in the following sections.
Gradual Publication for Supernodes
Although supernodes are assumed to have more available bandwidth than full nodes, we still need to utilise it efficiently to make the role of supernode accessible.
In the naive implementation of a supernode, every supernode reconstructs and publishes all data columns, leading to very fast publication at the cost of additional bandwidth and duplicates sent across the network. In our initial tests of the optimised branch we saw supernode outbound bandwidth averaging closer to 32MB per block proposal and considered ways to reduce this. We call the optimisation we came up with gradual publication, and it works as follows:
- Shuffle the data columns randomly on each node.
- Split the shuffled data columns into
Nchunks (we testedN = 4). - For each chunk, publish any columns that haven't already been seen on the P2P network, and then wait
DELAYmilliseconds before publishing the next chunk.
We tested with a DELAY equal to 200ms, meaning that for N = 4 a node spends at most 600ms before publishing its 4th chunk. In a network with multiple supernodes, many of the later chunks are already fully known by the network and do not need to be published at all. The randomisation means that each supernode takes on responsibility for propagating different columns, and the full set of columns remains likely to be available quickly.
We would like other client teams (or the spec) to adopt this optimisation and help us try different values of N and DELAY. It is possible we could reduce bandwidth requirements for supernodes even lower by finding the right set of parameters.
Test Setup
To evaluate the effectiveness of PeerDAS and the optimisations discussed above, as well as the feasibility of shipping PeerDAS with an increased blob count of 16, we tested our implementation on a larger network. A network of 100 nodes provides bandwidth metrics closer to a live environment, though some limitations remain:
- Latency in gossip messages will be lower than on a live network with thousands of nodes, where messages may take several hops to reach all peers.
- There is less variation in this test, as all nodes run the same software versions and are located in the same geographic region.
- The test doesn't account for bandwidth usage during long-range sync, as all nodes remained in sync for the test duration.
Nonetheless, with a peer count comparable to mainnet nodes, we expect to see similarly representative bandwidth results.
For the purpose of this experiment and to keep the setup simple and consistent:
- We run the test in a Kubernetes cluster using Kurtosis.
- We use the same machine types in the same region.
Client Software used
Lighthouse
We ran two test networks using two different Lighthouse configurations: one optimised, and one baseline.
- This branch contains the optimised implementation, with distributed blob building, fetching blobs from the EL and gradual publication optimisations.
- This branch contains the code used for the baseline comparison. It is similar to the
unstablebranch at the time of writing, with some adjustments to increase the blob count and fix an issue with discv5 under Kurtosis. - Known issues with the current optimised implementation:
- Occasional slow computation due to a race condition: With the "fetch blobs from EL" optimisation, supernodes now perform fewer data column reconstructions, because a block could be made available via EL blobs before data columns arrive via gossip. However, there's a race condition here, and reconstruction could happen at the same time as proof computation - this could slow down precomputation as both tasks are very CPU intensive. There's already an optimisation to this behaviour, but it didn't make it into this test.
- Proposer outbound bandwidth: The block proposers' outbound bandwidth hasn't actually been reduced here, because we don't check for duplication before publishing. Gossipsub does some amount of duplicate filtering, but we have implemented an extra check before publishing, which should reduce outbound bandwidth for nodes that are slow with proof computation. This optimisation didn't make it into this test either.
Reth
- This fork containing
getBlobsV1endpoint implementation and an increased blob count to 16 blobs. - At the time of writing, multiple execution clients already have this endpoint implemented and merged, including Reth, Nethermind, and Besu.
Network Parameters
MAX_BLOBS_PER_BLOCK: 16NUMBER_OF_COLUMNS: 128DATA_COLUMN_SIDECAR_SUBNET_COUNT: 128CUSTODY_REQUIREMENT: 8*
*CUSTODY_REQUIREMENT is increased from the current spec value 4 to account for minimum validator custody and subnet sampling.
Network Structure
The network is designed so that:
- Each Lighthouse node has 99 peers, comparable to a live network.
- A varied number of CPU cores are used, allowing us to analyse individual computation times.
- Some nodes are configured to publish only blocks, simulating the inability to compute and publish blobs before the attestation deadline.
| Node Type | Number of Nodes | Logical CPU Cores | Proposer Publish Block + Data Columns |
|---|---|---|---|
| Supernode | 10 | 16 | Blocks and all data columns |
| Supernode | 10 | 8 | Blocks and all data columns |
| Fullnode | 20 | 8 | Blocks and all data columns |
| Fullnode | 20 | 4 | Blocks and all data columns |
| Fullnode | 10 | 8 | Blocks and 50% of data columns |
| Fullnode | 10 | 4 | Blocks and 50% of data columns |
| Fullnode | 10 | 8 | Blocks only |
| Fullnode | 10 | 4 | Blocks only |
Kurtosis config used can be found here.
For brevity, we present metrics below for 5 classes of nodes:
- Supernodes with 16 cores (16C)
- Full nodes with 8 cores (8C)
- Full nodes with 8 cores publishing 50% of data columns
- Full nodes with 4 cores publishing 50% of data columns
- Full nodes with 4 cores publishing no data columns
The impact of the other classes of nodes is still captured indirectly in the metrics for our selected classes. We found that results were often similar across node type, publication percentage and core count, so the 5 selected are sufficient for a summary. In the future, we may run with less node types to simplify analysis.
Metrics
We present metrics below for the baseline testnet running the variant of unstable, and the optimised testnet including fetch-blobs, decentralising blob building, and gradual publication.
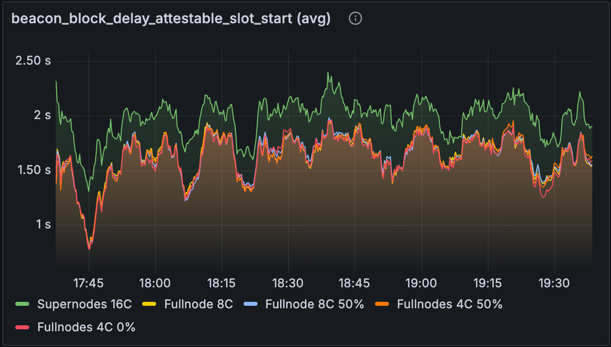
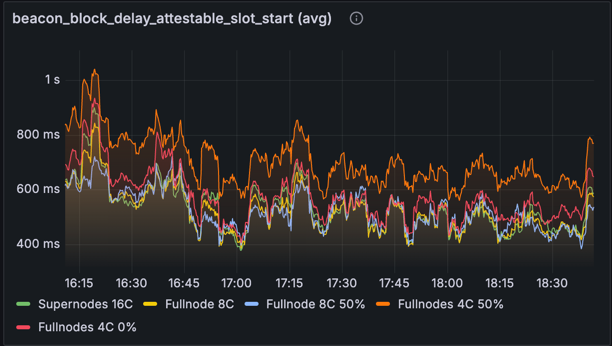
Block Attestable Time
metric: beacon_block_delay_attestable_slot_start (avg)
| BASELINE | OPTIMISED |
|---|---|
 |
 |
The charts above show the average delay from the start of the slot before blocks becomes attestable (lower is better). Ideally, we want all blocks to be attestable before 4 seconds into the slot, and we see from this chart that this is true on average for the full range of node types.
In the baseline network, the supernodes perform worse, roughly 500ms slower on average - this is likely due to the unoptimised approach to data column reconstruction, which is performed every slot and blocks are only made available after reconstruction. This has been optimised to make reconstruction non-blocking, allowing blocks to become attestable as soon as the node receives all data columns from the gossip network (supernodes require and custody all data columns). However, you'll notice a different trend in the optimised version, as reconstruction is triggered less often due to blocks being made available from EL blobs.
In the optimised network, We see significant improvements across all node types, as blocks are made attestable as soon as all blobs are retrieved from the EL, or received via gossip from distributed blob building. The 4 core nodes are a little slower than the 8 and 16 core ones, which is expected due to the higher CPU contention caused by other work. We can't explain why the Fullnodes 4C 0% class outperforms its 50% counterpart, as publishing is unlikely to cause strain on the CPU.
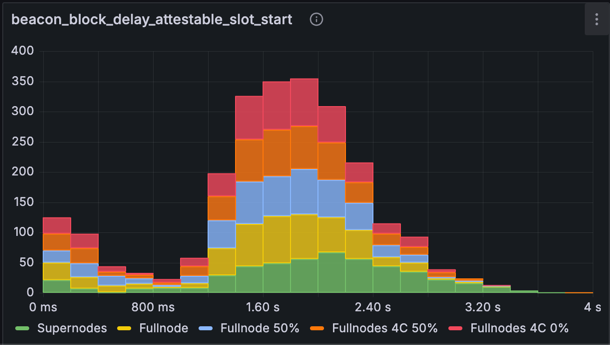
metric: beacon_block_delay_attestable_slot_start (without time-based averaging)
| BASELINE | OPTIMISED |
|---|---|
 |
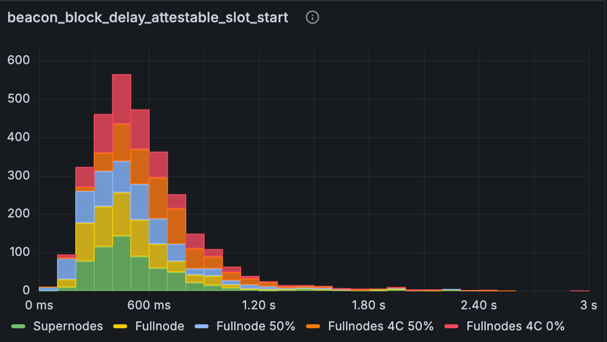 |
The histograms above show the attestable delay without time-based averaging. Observing the baseline numbers, we see a heavier tail exceeding 3 seconds and small number of values nearing 4 seconds - approaching the attestation deadline. After optimisation, the results show marked improvement: while there's still a tail out to 3 seconds, all blocks remain safely below the 4-second cutoff for attestations. Mainnet-sized networks are likely to have more transactions & attestations which will impose some additional processing time, but the attestable time will likely remain under the 4s threshold much of the time. Some future optimisations we have in mind will likely help here too.
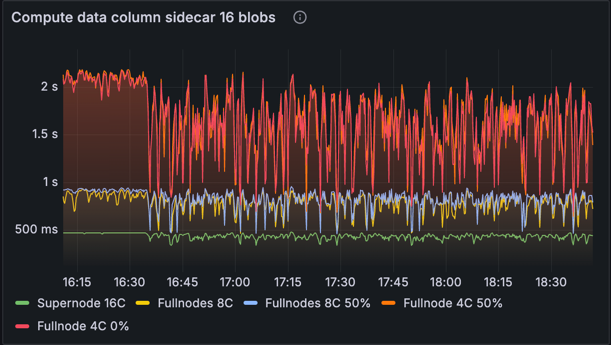
Proof Computation Time
| Time Series | Average |
|---|---|
 |
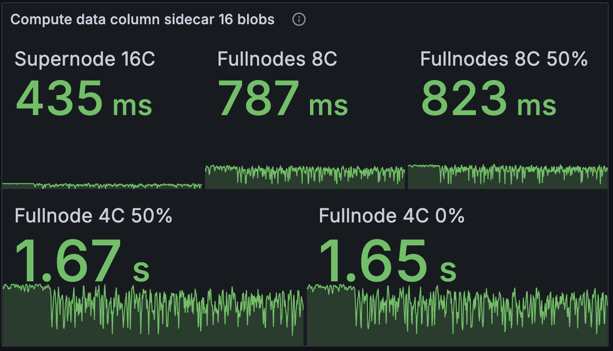 |
This metric tracks the time taken to compute data column sidecars: including cells, cell proofs and inclusion proofs. This computation is parallelised, so we observe the machines with more cores outperforming the lower spec ones. This chart demonstrates the importance of the supernodes for the network, as they are able to quickly compute proofs and start publishing them. In the case where the proposer's node has inadequate resources to compute the data column sidecars quickly, the supernodes can compute them using the blobs from the EL mempool and start propagating them. There are no differences here between the baseline and optimised networks, as there's no optimisation made to proof computation.
Data Column Gossip Time
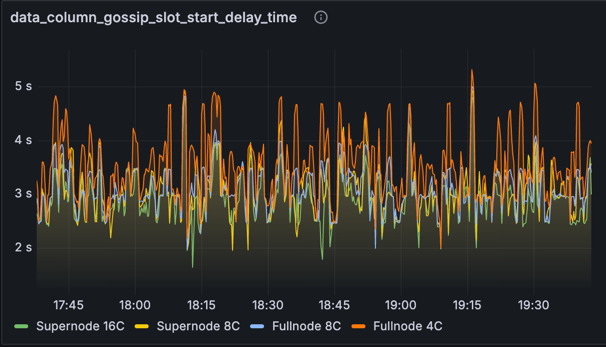
metric: data_column_gossip_slot_start_delay_time
| BASELINE | OPTIMISED |
|---|---|
 |
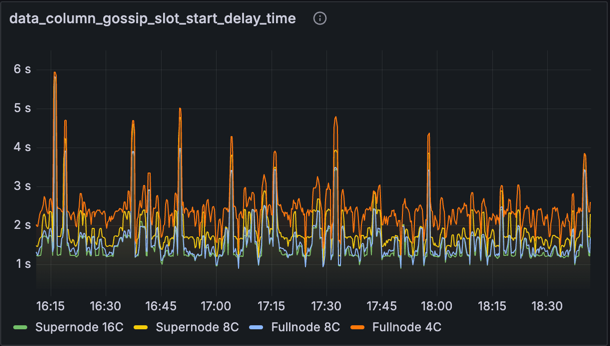 |
This chart shows the time that data column sidecars are received relative to the start of the slot at which they were published. Interestingly, we see some spikes greater than 4s here, especially on the full nodes. Despite these spikes, the blocks at these slots were still becoming attestable prior to 4s (per the previous charts for attestable delay). We suspect the reason for this is that nodes can mark blocks as available and attestable sooner than 4s by processing blobs from the EL mempool. This demonstrates the strength of the mempool approach: that it can smooth out what would otherwise be significant delays in data availability. However, this same strength is also a potential weakness, as it means poor availability of a blob in the mempool could lead to a block being processed late and subsequently reorged. In a future test we would like to incorporate some "private" blob transactions from outside the mempool to ensure the network is capable of including them without causing data availability issues.
Outbound Data Column Bandwidth
The outbound bandwidth is the amount of blob-related data sent to peers using Lighthouse's gossipsub protocol.
The first set of charts below show the maximum amount of data sent in a 12s period by a node in any given class. The headline number is the maximum over time (maximum of maximums).
The second set of charts below show the average amount of data sent in a 12s period by all nodes in any given class. The headline number is the average over time (average of averages).
Note that most blocks in the test contain 16 blobs, so the numbers here are much higher than under normal conditions in a live network, likely around 2x higher given a target blob count of 8.
The yellow charts are from the baseline network, and the red from our optimised network.
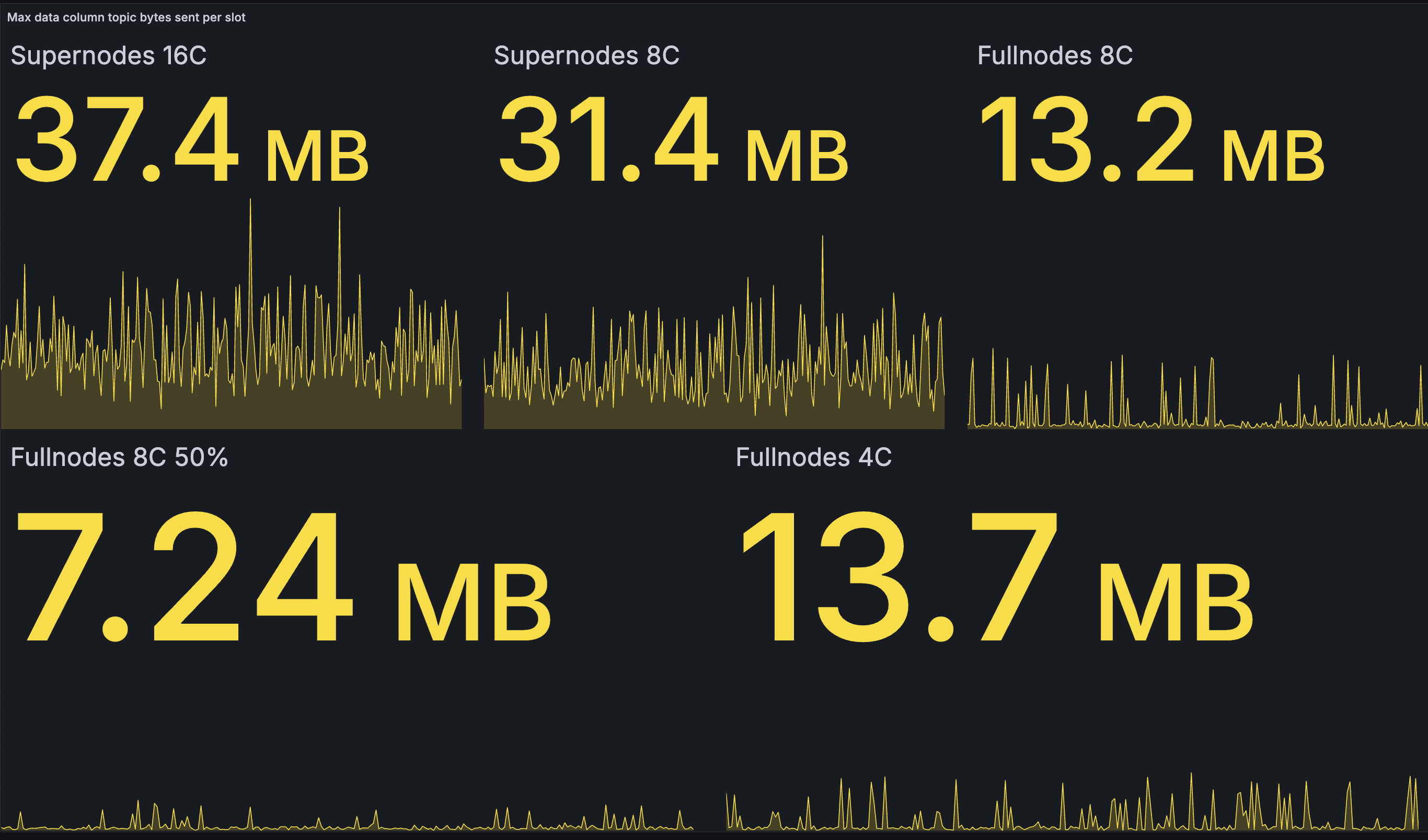
Outbound data column bandwidth per slot (max):
| BASELINE | OPTIMISED |
|---|---|
 |
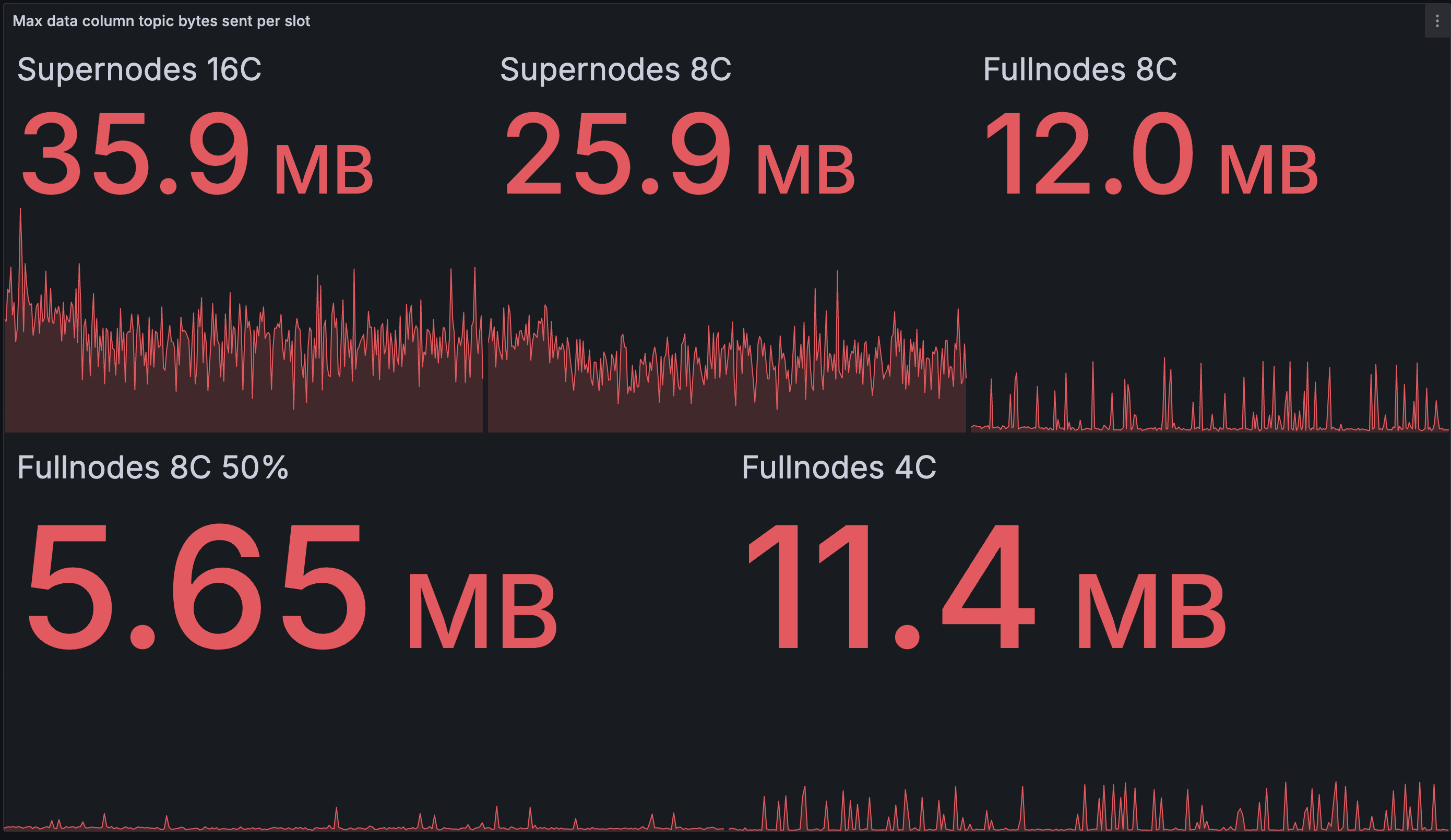 |
We see only a modest reduction in outbound bandwidth compared to the baseline testnet. The greatest beneficiaries are the 8-core supernode with a saving of 17.5%, and the 8-core fullnode publishing 50% with a saving of 22%. The spikes for the full nodes are unfortunately higher than necessary due to the suboptimality identified after testing: full nodes do not seem to check whether data columns are already known before publishing them. However, we're not 100% sure about this and will investigate further.
In the baseline network, supernodes will sometimes end up publishing 50% of the data columns for a block. The fastest nodes will complete reconstruction after receiving 50% of data columns, and then start blasting the remaining 50% of reconstructed columns out to the network. The slower 8-core supernodes finish reconstruction on average a bit later than the 16-core ones, and by this time there are less novel columns to publish (ones not yet seen on gossip), so they end up publishing a little less.
In the optimised network, the amount of data published is still correlated with core count because the faster nodes still begin publishing earlier - at a time when more of the columns are novel. However, we suspect that the amount of data is dependent on the number of supernodes and the configuration of the gradual publication algorithm. In our current test with 4 batches separated by waits of 200ms, it seems that supernodes are still publishing quite a similar amount of data in the worst-case, which naively might correspond to 50% of data columns (2 batches). Lengthening the batch interval or shrinking the size of batches could be a way to reduce this in future tests.
Below we look at the average outbound bandwidth.
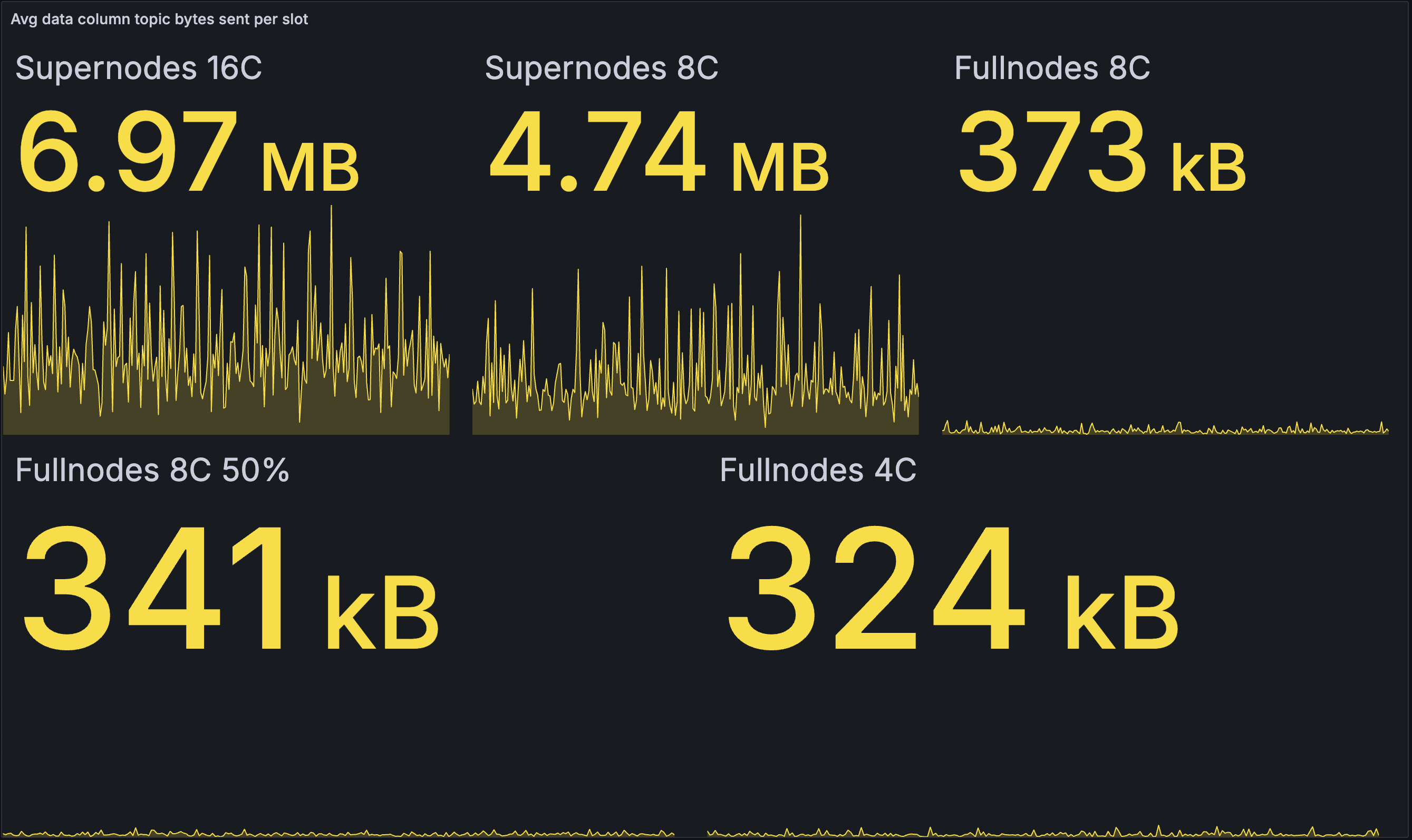
Outbound data column bandwidth per slot (avg):
| BASELINE | OPTIMISED |
|---|---|
 |
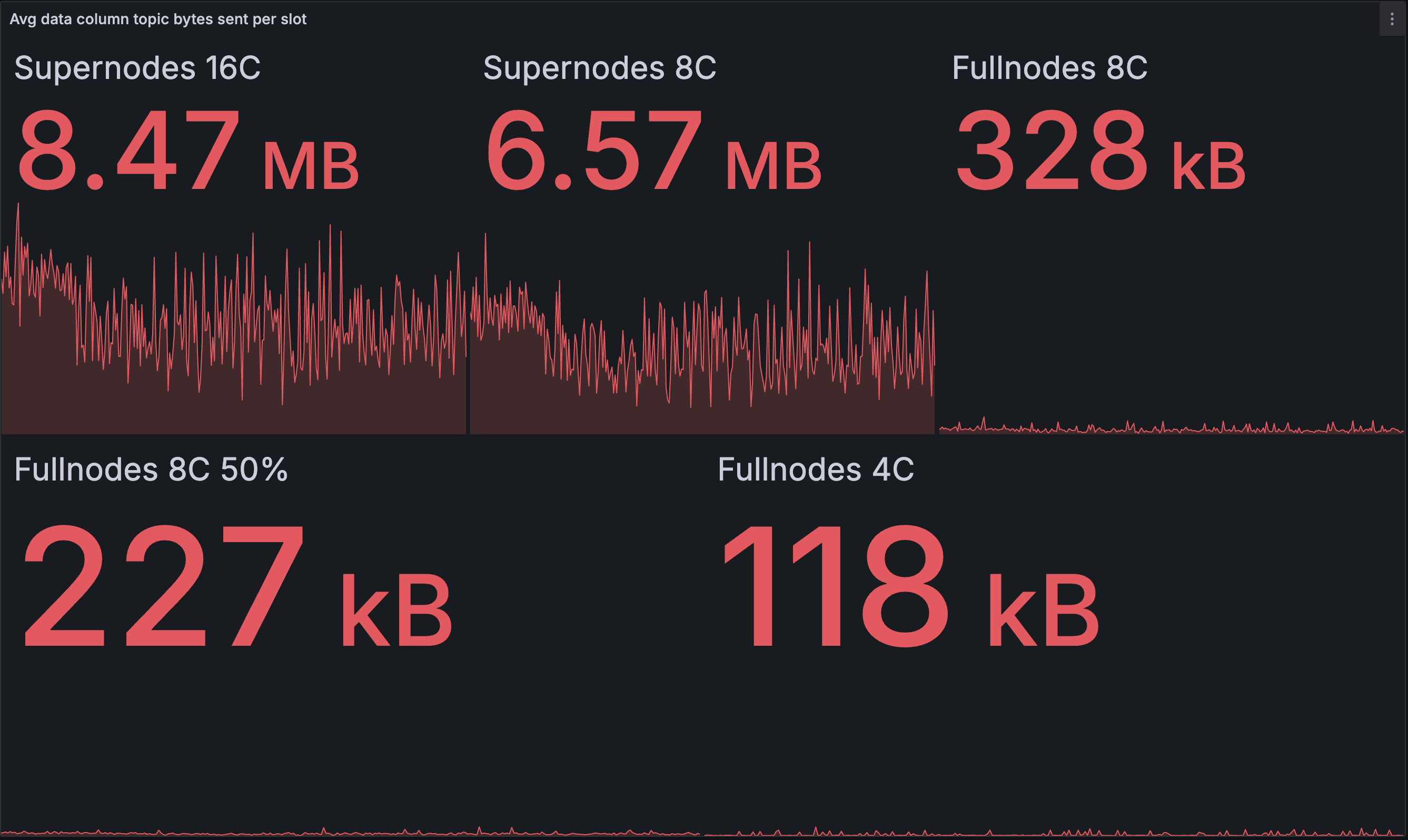 |
Here we see that the optimised network puts a higher load on the supernodes on average, with reductions for the full nodes. This makes sense, as the supernodes are able to propagate the blobs to the full nodes more quickly, reducing the need for gossip between full nodes. As mentioned above, further reducing the bandwidth for the supernodes may be possible by tweaking the parameters of gradual publication.
Note that the averaging also hides the spikes from full node block publication -- they are better represented by the max data above.
Inbound Data Column Bandwidth
The inbound data column bandwidth is the amount of blob-related data received from peers using Lighthouse's gossipsub protocol.
The charts below show the average amount of data received in a 12s period by all nodes in each class. The headline number is the average over time (average of averages).
The yellow charts are from the baseline network, and the red from our optimised network.
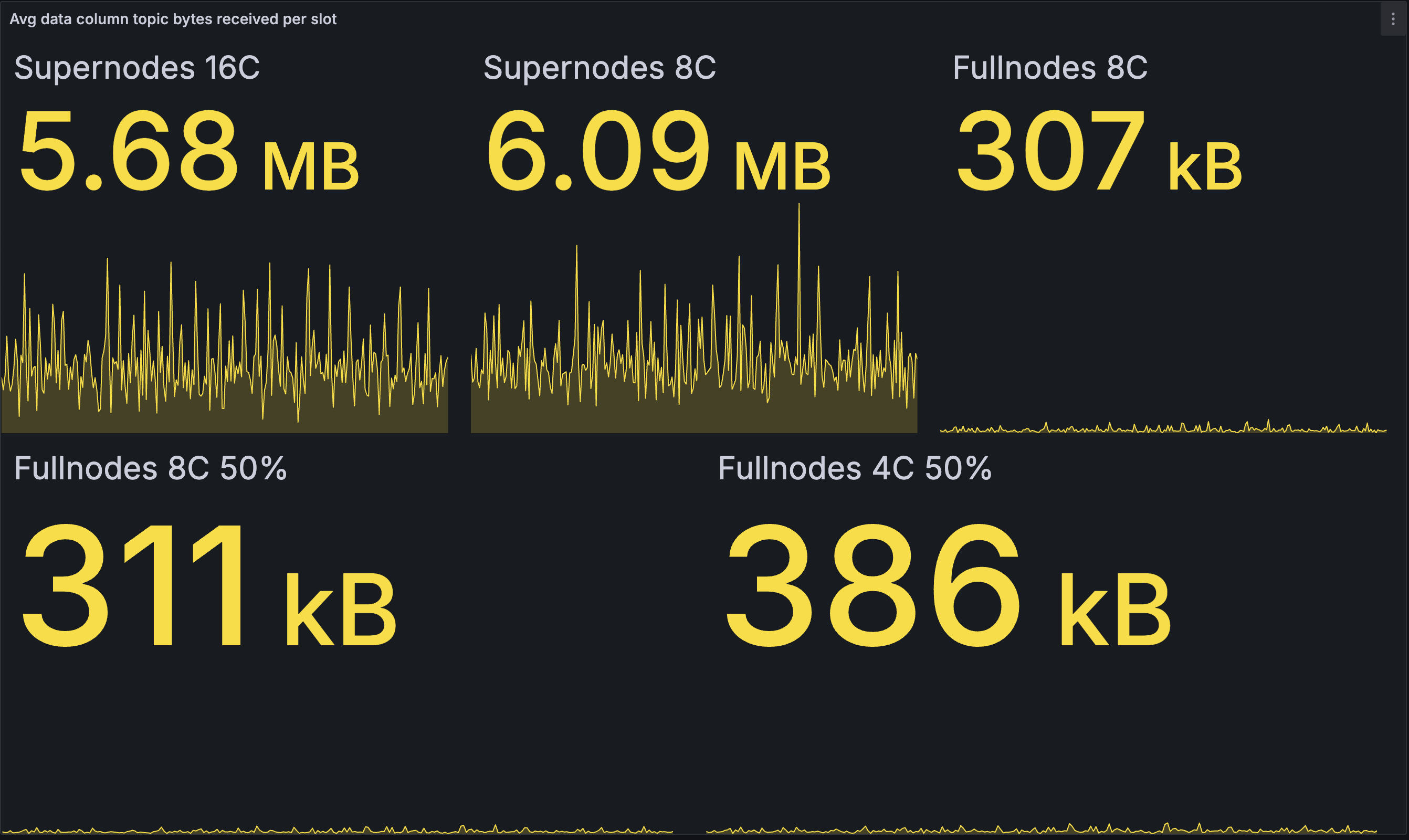
Inbound data column bandwidth per slot (avg)
| BASELINE | OPTIMISED |
|---|---|
 |
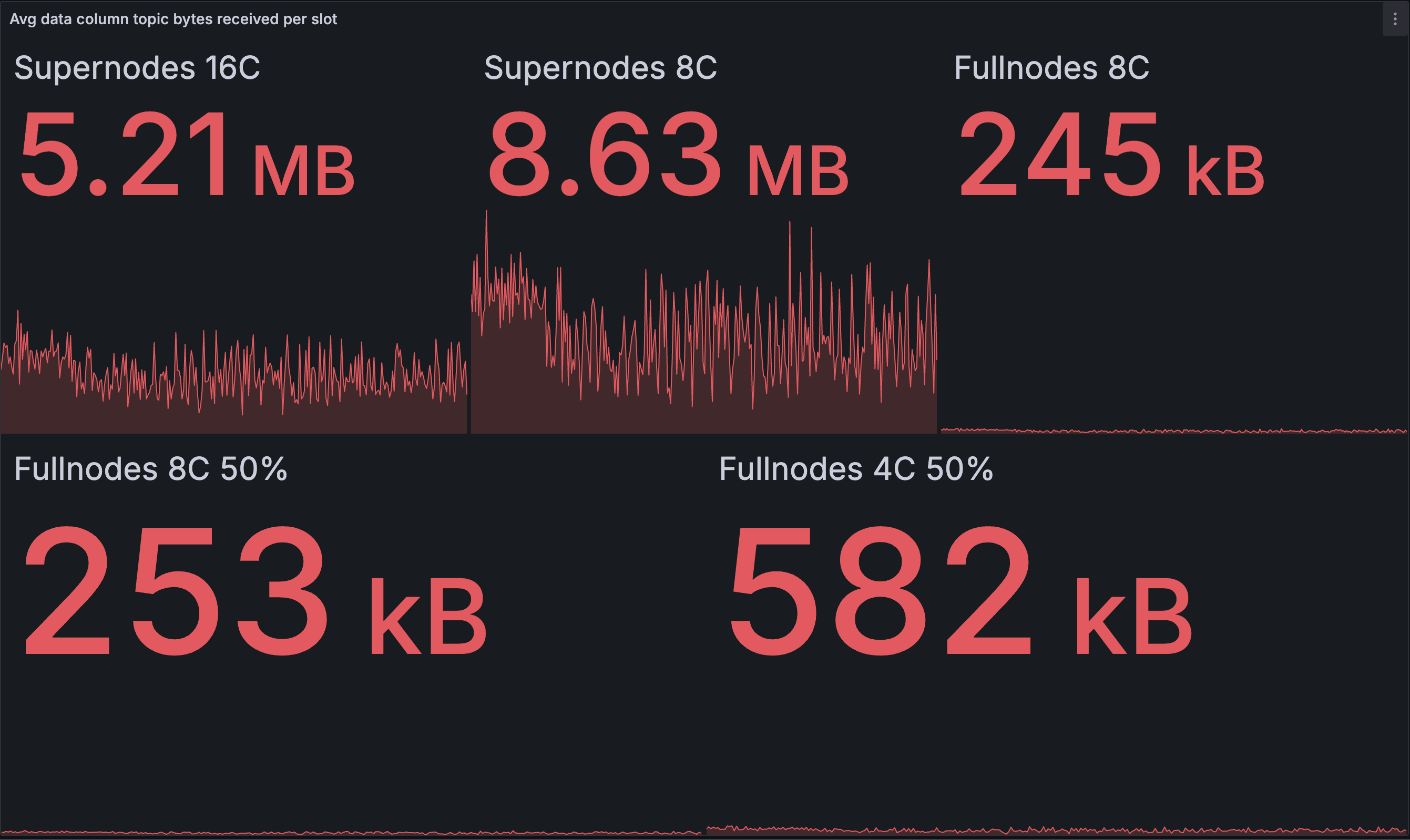 |
Amongst the supernodes we see an interesting contrast: the 16 core node is downloading slightly less compared to the baseline, while the 8 core node is downloading slightly more. This suggests two different effects acting in opposition to each other. We hypothesise that the first effect could be that fast supernodes in the optimised network are receiving the full set of blobs from the EL prior to reconstruction finishing, and are beginning data column publishing earlier, leading to more data published and less downloaded. This is consistent with the increased outbound bandwidth for supernodes as well.
We suspect the second effect is that more duplicate data columns are published (and downloaded) in the optimised network. In the baseline network, supernodes begin publishing only after completing reconstruction, so the slower supernodes end up self-limiting their publication. In the optimised network, all supernodes start publishing at approximately the same time, assuming the time to fetch blobs from the EL is not strongly correlated with core count. As a result, more duplicate messages are published near simultaneously, and there is some waste as these are downloaded by peers of the supernodes (both supernodes and full nodes).
We are hoping that future tests will prove or disprove our hypotheses, as we found it hard to extract these theories from our data, and impossible to validate them using this initial experiment.
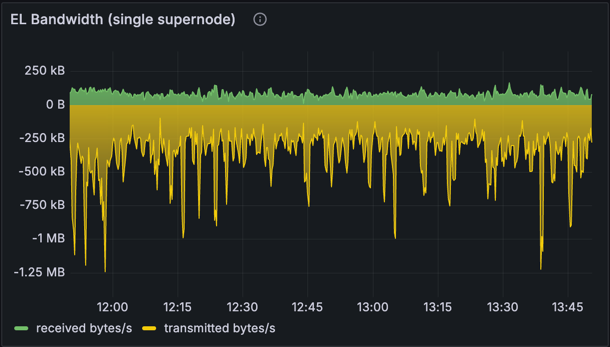
Execution Client (EL) Bandwidth
| EL bandwidth for a single node | EL bandwidth average |
|---|---|
 |
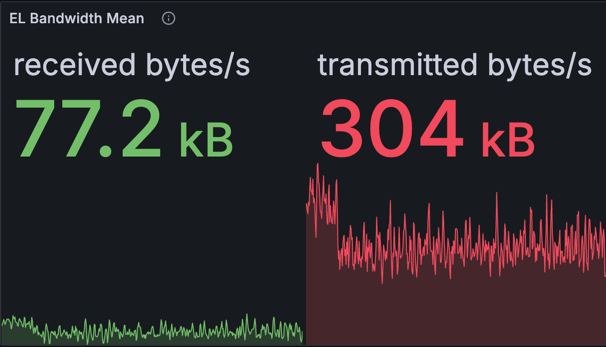 |
The charts above display the inbound and outbound bandwidth of the EL (Reth). Note that the outbound bandwidth captured here includes data from the CL and EL interactions (JSON-RPC calls such as getBlobsV1 and getPayloadV3), does not accurately reflect the outbound bandwidth in a typical setup where CL and EL reside on the same machine.
However, we could calculate a rough estimate of outbound bandwidth:
- Total outbound is calculated as 304 KB/s * 12 seconds = 3.65 MB per slot.
- Adjusting for
getBlobsV1usage, which is 128 KB per blob * 16 = ~2 MB per slot, we get approximately 1.48 MB per slot or 126 KB/s spent on outbound bandwidth.
In practice, it's unlikely that we'd consistently exceed the target blob count of 8 due to fee structures. Even if we operate at 16 blobs, the calculated EL bandwidth remains manageable.
Impact on Node Operators
The PeerDAS network parameters were designed to minimise the impact to network operators and to maintain the same bandwidth numbers as 4844 (See Francesco's ethresearch post here). Therefore, during normal operation, we'd expect the bandwidth for a fullnode to be similar to mainnet today. During block proposal, we expect to see a spike in CL outbound bandwidth due to blob propagation, and we've worked hard to make sure increasing blob count with PeerDAS do not make home staking unfeasible - more on this below.
Bandwidth Usage Comparison across Node Types
The below table shows the average bandwidth results from this test:
| Node Type | CL inbound | CL outbound | Total inbound (inc. EL*) | Total outbound (inc. EL*) |
|---|---|---|---|---|
| Fullnode | 356 KB/s | 241 KB/s | 433.2 KB/s | 367 KB/s |
| Supernode | 1.12 MB/s | 1.07 MB/s | 1.2 MB/s | 1.2 MB/s |
*See above section for EL bandwidth numbers.
Supernodes consume much higher bandwidth on the CL side due to the number of data columns they sample and store (inbound bandwidth), and the number of data columns they help propagate with distributed blob building (outbound bandwidth). The EL numbers are similar across both node types and are relatively low compared to the CL.
During block proposal, we see spikes of up to 1 MB/s over a 30 seconds period, or ~12 MB per slot for all nodes. However, this will likely be reduced once we optimise to de-duplicate data column publishing.
Storage Requirement
We didn't look at the actual storage usage in the test, however this can be calculated based on the parameter MIN_EPOCHS_FOR_BLOB_SIDECARS_REQUESTS or MIN_EPOCHS_FOR_DATA_COLUMN_SIDECARS_REQUESTS, which represents the number of epochs each node keep the blob data for, which is currently set to 4096, or approx. 18 days.
Comparing with Deneb, where nodes store all blobs:
| Node Type | Deneb target (3) | Deneb max (6) | PeerDAS target blobs = 8 | PeerDAS max blobs = 16 |
|---|---|---|---|---|
| Fullnode* | 50.33 GB | 100.66 GB | 16.78 GB | 33.55 GB |
| Supernode | 50.33 GB | 100.66 GB | 268.44 GB | 536.87 GB |
- *Calculated based on custody column = 8 (for fullnodes with 1-8 validator attached)
- **Note that in practice, it's not possible to consistently reach max blobs per block due to how blob fees are calculated, however we've included the theoretical max number here for reference.
The storage requirement for fullnodes has reduced from 50.33 GB to 16.78 GB due to them only storing a subset of blob data (8 out of 128 columns), despite the increase in max blob count to 16.
Home Stakers Building Local Blocks
Based on the minimum hardware requirements (quad-core CPU) for staking today (from EthStaker), a block with 16 blobs will take an average quad-core CPU 1 - 2 seconds to compute proofs, and potentially even longer to propagate to the network on average consumer grade internet (25-50 Mbps) in Australia.
Therefore, these proposers will have to largely rely on distributed blob building and other nodes to help compute and propagate the blobs across the network. The CL client will have to make sure the signed beacon blocks are distributed as soon as possible, so other nodes can start building cell proofs. From our tests, we've used 4 logical core machines to represent these nodes, and they have been able to produce blocks with 16 blobs with the same success rate as other node types. Therefore, we don't anticipate bumping the hardware requirement for home stakers even if we increase blob count to 16 with PeerDAS, and the hardware today should be sufficient. The minimum hardware requirement is expected to be raised in the longer term, although we'd prefer this to happen naturally and smoothly as technology advances over time.
Home Stakers Using MEV Relays
For home stakers using MEV relay(s), the blob proof building and propagation work is outsourced to the external block builder, therefore there should be minimal impact to these users, assuming the external block builders have sufficient hardware and bandwidth to propagate the block and blobs. They could also benefit from distributed blob building, if all blob transactions included in the block are from the public mempool. We don’t expect these stakers will need to upgrade their current hardware or bandwidth.
Professional Node Operators
With validator custody, the number of custody data columns increases as the ETH balance of attached validators grows - 1 extra custody column per 32 ETH. Nodes with more than 128 validators are required to run as supernode, custodying all columns. Professional node operators will likely be running supernodes and experience increased CPU and bandwidth usage, due to the number of validators attached to their nodes. These validator nodes have higher stakes and are therefore expected to validate more data to ensure the network's safety.
The hardware requirements for large node operators are not yet known at this stage, as they depend on the optimisations we end up implementing. While a hardware upgrade may or may not be necessary, we do expect an increase in bandwidth due to the volume of data columns being received and sent. The metrics, illustrated earlier, reflect this, and we will continue working to keep Lighthouse as efficient as possible, including reducing bandwidth usage where feasible.
Future Work and Optimisations
This goal of this post is to share our progress on PeerDAS and our efforts in solving the proposer bandwidth problem while demonstrating the possibility of scaling up to 16 blobs without sacrificing decentralisation of the network.
We've identified many potential optimisations along the way, and we expect more improvements before PeerDAS is shipped. Some future work and optimisations include:
- Peer Sampling: The current version of PeerDAS uses "Subnet Sampling," where nodes subscribe to gossip topics to perform sampling. This method requires more bandwidth than "Peer Sampling," where nodes send RPC requests to peers to retrieve data columns. The gossip protocol consumes more bandwidth because messages are broadcast to many peers simultaneously. Implementing Peer Sampling will significantly reduce bandwidth usage and enable further scaling.
- KZG library optimisation: At the time of testing, cell proofs for each blob takes 200 ms to compute on a single thread. At the time of writing this, proof creation time has been brought down to 150 ms (as of
rust-eth-kzgv0.5.2). This improvement allows data columns to propagate over the gossip network sooner. - Proof pre-computation: There's a proposal to pre-compute cell proofs and propagate them over the gossip network, allowing block builders to publish their blocks and blobs at the start of the slot. This could save roughly 150 ms by eliminating the need for proof computation at the start of the slot.
- Distributed Blob Building with workload spread across all nodes: The current form of distributed blob building requires all blobs to be present before the nodes can compute and broadcast the cells and proofs. This is because the blob data are transported over the gossip network as
DataColumns rather thanCells. As a result, the number of blobs we can scale to is roughly limited by the number of CPUs a supernode has. For example, as a node with 16 logical CPUs can produce proofs for 16 blobs in parallel and therefore achieve minimal computation time (~150ms). To comfortably scale beyond 16 blobs, it would be more efficient to distribute the proof building workload across more nodes, e.g. each node could build and publish proofs for 3 blobs. This approach would reduce the heavy reliance on supernodes and alleviate the strain on them.
Conclusion
This post has detailed our progress on PeerDAS and our collective effort across client and research teams to scale Ethereum's data availability layer. The proposed optimisations - such as fetching blobs from the EL and distributing blob building - have shown clear benefits:
- Reduced block import latency, allowing blocks to become attestable faster.
- Improved blob propagation, making the network more resilient.
- Scaling without compromising decentralisation, ensuring home stakers can continue participating with consumer-grade hardware.
Throughout this process, we've gained valuable insights and identified further opportunities for optimisation and improvement. We're excited to continue building on this work and to bring more sustainable scaling to Ethereum.
Thank you for reading and I hope you find it interesting! :)
A special thanks to Lion and Pawan for reviewing this work, Age and Anton for helping with testing and infrastructure, and Kev for helping us with various KZG library performance improvements.
References
- From 4844 to Danksharding: a path to scaling Ethereum DA - Francesco
- Get blobs from the EL's blob pool - Michael Sproul
- PeerDAS proposer bandwidth problem discussion - Eth R&D Discord
- Fetch blobs from EL pool - Dapplion
- How to help self builders with blobs - Dankrad Feist