

 A detailed postmortem of the Holesky incident can be found here.
A detailed postmortem of the Holesky incident can be found here.
A very informative talk by dapplion on the dangers non-finality poses to the Ethereum network can be found here.
On February 24th, 2025, shortly after the Pectra upgrade on Holesky, users began reporting invalid execution payload errors. Execution Layer (EL) and Consensus Layer (CL) developers across multiple teams immediately began investigating these error reports. Within an hour it was discovered that Geth, Nethermind and Besu incorrectly accepted an invalid block due to a misconfigured depositContractAddress value.
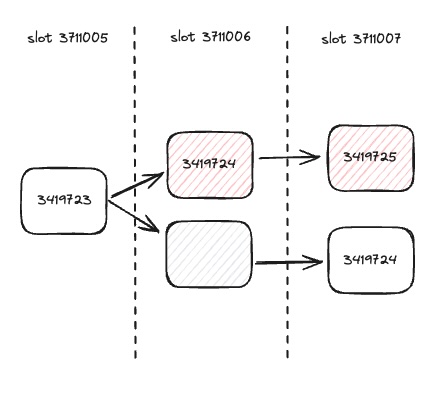 At slot 3711006 an invalid block (block 3419724 shaded in red) is proposed. Geth, Nethermind and Besu incorrectly accept the invalid block, creating a fork. All chains originating from the original invalid block (also shaded in red) are therefore invalid.
At slot 3711006 an invalid block (block 3419724 shaded in red) is proposed. Geth, Nethermind and Besu incorrectly accept the invalid block, creating a fork. All chains originating from the original invalid block (also shaded in red) are therefore invalid.
The relevant EL teams quickly pushed out a patch to fix this misconfigured value, but by this point the damage to the network had already been done. Since a super-majority of the network was running either Geth, Nethermind or Besu, a super-majority of the network had attested to an invalid block. Due to this, all CL clients began struggling to build upon and attest to the canonical chain. This put the Holesky network into a long period of non-finality.
What is non-finality and why is it bad?
Finality is an important mechanism in Ethereum. If enough validators attest to the head of the chain for a long enough period of time, everything before a certain checkpoint becomes finalized. Under healthy network conditions this checkpoint, referred to as the finalized checkpoint, is current_epoch - 2. Anything before the finalized checkpoint can no longer be reverted unless at least 2/3rds of all Ethereum staked is burned. When finality is reached, Consensus Layer clients can:
- Prune data earlier than the finalized checkpoint.
- Ignore gossipsub messages from before the finalized checkpoint.
- Ignore any fork-choice related data earlier than the finalized checkpoint.
- Perform other miscellaneous optimizations.
Ethereum is referred to as being in a period of non-finality anytime the most recent finalized checkpoint epoch is less than current_epoch - 2. Because CL clients are unable to prune data and ignore network messages for non-finalized epochs, long periods of non-finality can be quite chaotic.
When Ethereum enters a period of non-finality greater than four epochs, a special mode called "inactivity leak" is activated. This emergency mode allows the network to punish validators who haven't been performing their scheduled duties. These punishments increase quadratically with time. If enough time passes, validators who aren't performing their scheduled duties will be penalized to the point where they will be forcefully exited from the network. During periods of non-finality, when inactivity leak penalties spike, the Beacon State is expected to increase in size.
What is a Beacon State and why is it so big?
The Beacon State is a data structure that is at the heart of the Ethereum consensus layer. It stores the full state of the chain at any given time. Data like historical block roots, genesis time, the current fork, validator balances and inactivity penalities are just a subset of values that are stored inside the Beacon State.
The most recent state (the advanced Beacon State) is needed to process new blocks, enforce fork choice rules and other critical consensus layer operations. Many of these tasks are time sensitive so storing these recent states in a cache is important for CL client performance.
Cache: A storage area that holds frequently accessed data in memory enabling faster retrieval compared to storing on disk. If you're Australian you may be pronouncing this word incorrectly.
Older states may be needed to process peer to peer networking requests or provide historical data about the chain. Caching these older states may not always be desirable.
Beacon states are expensive to lookup in part because they are so big. A single state on Holesky, during healthy network conditions, is roughly 200MB in size. Lighthouse uses memory optimization techniques on beacon state objects to "recycle" memory in a structured way. For example, if we were to look at a set of beacon state objects for some range of slots, much of the data for these individual states would be similar. Using memory optimizations techniques, Lighthouse can have these beacon state objects share memory across these similar values. This helps reduce overhead caused by frequent memory allocations/deallocations and reduces overall memory usage.
During the Holesky non-finality incident, inactivity leak penalties added roughly 70MB of new data to the Beacon State at each epoch boundary. Lighthouse memory optimization techniques were not being applied to the Beacon States inactivity_score field, which tracks these penalties for each validator. As a result, beacon states consumed significantly more memory than under normal network conditions.
Lighthouse, Non-Finality, Syncing, Disk Space and OOMs
Syncing
Consensus Layer clients rely on a process called Optimistic Sync to catch up to the head of the chain. During Optimistic Sync, execution payloads are not verified. Instead the CL's rely on fork choice to sync the chain. The chain with the heaviest attestation weight is considered canonical by fork choice standards. Furthermore, once fork choice sees a justified checkpoint, it will ignore blocks that aren't descendant from that justified checkpoint.
The bad block that triggered the Holesky non-finality incident was attested to by a super-majority of the network and had become part of a justified checkpoint. As a result, Lighthouse nodes effectively became stuck and could not sync onto the good chain. To solve for this, the team introduced an invalid-block-root CLI flag to allow node operators to ignore specific block roots and their descendants. With this change, peers serving blocks from the invalid chain were automatically banned and the bad attestations were ignored by fork choice. This made it easier for Lighthouse nodes to find good peers and sync onto the good chain.
But this didn't completely resolve syncing issues on Holesky. Though Lighthouse nodes were able to ignore the invalid block and its descendants, finding good peers was still a struggle. Two new syncing tools were added to allow for quicker and more reliable syncing. The first was a Lighthouse CLI program named http-sync which allows a Lighthouse node to connect and sync with an already synced consensus client. Though extremely useful, from a UX perspective this method is a bit complicated and also requires direct access to a synced node. A second, more user friendly, syncing tool was added in the form of a new endpoint, add_peers. With add_peers a node operator is able to manually add a trusted peer, via its Ethereum Node Record (ENR), that it knows to be serving the canonical chain. By using this endpoint and disabling peer discovery (with the --disable-discovery flag) syncing becomes much quicker and more reliable during chaotic network conditions.
Peer Discovery: The process in which an Ethereum node finds other peers on the network to exchange data with.
In the future, we are looking to introduce a non-finalized checkpoint sync mechanism that can help rescue nodes during long periods of non-finality. This will allow node operators to sync to an epoch that isn't finalized, giving them additional ways to keep their node running during adverse network conditions.
If this feature was available during the Holesky non-finality incident, node operators could have checkpoint synced to a non-finalized epoch that was further along than the epoch containing the bad block. This would have allowed operators to quickly sync to the good chain, and ban peers serving them the bad chain. Furthermore, if a network stays un-finalized for more than a few weeks, this feature is required to safely rescue the network. This is because forward syncing blocks older than the data availability window is unsafe.
Data Availability Window: The Deneb fork introduced blobs to the Ethereum network. Nodes are required to store blobs for 18 days, i.e. the Data Availability Window, before they can be pruned.
During long periods of non-finality, without non-finalized checkpoint sync, nodes would be forced to forward sync without being able to independently verify the contents of the blocks they are syncing with. This is unsafe for individual nodes and for the network as a whole.
Disk Space
Lighthouse stores its data on disk across two databases, the hot DB and the freezer DB. The hot DB manages non-finalized data. Under healthy network conditions it stores data between current_epoch and current_epoch - 2. The freezer DB manages finalized data. The freezer DB uses a sophisticated diff-based storage strategy, known as Tree-States, to optimize disk usage.
When a portion of the blockchain finalizes, Lighthouse initiates a database migration, transferring recently finalized data from the hot DB to the freezer DB. During these migrations any side chains that are not children of the new finalized state are pruned.
During the non-finality incident, Lighthouse nodes were unable to perform database migrations and side chain pruning. Disk usage quickly ballooned from roughly 20GB to 100's of GB, eventually exceeding 1TB! Since the hot DB lacks a diff-based storage strategy, individual beacon states were being stored in their entirety. There were also thousands of side chains being stored in the hot db further compounding disk space issues. The Lighthouse DB strictly enforces an invariant which requires that the intermediary state of a skipped slot is stored. These side chains mostly consisted of skipped slots. As a result, Lighthouse was storing intermediary states for many skipped slots across thousands of side chains.
Skipped slot: A slot in which there is no block. This usually happens if a block proposer proposes an invalid block, or the block proposer for that slot is offline. In the case of the Holesky incident, proposers were proposing blocks on the chain they were currently synced to. Even if a block proposer was synced to the canonical chain and successfully proposed a valid block, other side chains could have registered the slot as skipped.
To work around this issue, the team introduced a new endpoint that allows node operators to trigger pseudo finalization in the database. The endpoint requires operators to provide an epoch, block root and state root from an epoch boundary. Any side chains not descended from the provided epoch boundary block are pruned. Additionally, data from earlier than the provided epoch are migrated from the hot DB to the more disk efficient freezer DB.
We are also working on adding a diff-based storage strategy to the hot DB. Nicknamed Hot Tree-States, this feature will help reduce disk space usage in healthy and adverse network conditions. We've already tested this feature during the Holesky non-finality incident and saw a drastic reduction in disk space usage versus regular Lighthouse nodes.
Out of Memory (OOM)
Lighthouse utilizes multiple in-memory caches to provide fast data access while minimizing read latency and disk I/O. The state cache is used to store useful/recently accessed states. By default this cache is limited to storing up to 256 states and is frequently culled to remove stale data.
Lighthouse triggers state lookups when serving data to peers over the network, for example when serving non finalized blocks, blobs and status requests. When a state lookup is triggered, if the state doesn't exist in the state cache, it will be fetched from the database and inserted into the state cache. State lookups are expensive computations, especially when fetched from the hot DB.
During Holesky non-finality, most peers were requesting non-finalized blocks and blobs as they tried syncing their local view of the chain. Since serving this data required Lighthouse to execute state lookups, Lighthouse nodes quickly became overwhelmed and OOM'd.
OOM: An out of memory exception. This happens when a computer has no additional memory left to be allocated for use by a program.
Lighthouse executes state lookups when serving non-finalized blocks and blobs to peers, because it needs a way to calculate which block roots are related to which range of slots the peer is requesting. For finalized data, block roots are stored as a slot/block root mapping. Figuring out which block roots are tied to which slots is trivial and requires no state lookups. For non-finalized data this is a bit trickier, because re-orgs and other side-chains can conflict with our view of this slot/block root mapping. Instead we use the beacon state to compute the range of block roots for a given range of slots. During healthy network conditions, this was a fine option. But in periods of non-finality, peers were almost always requesting blocks from the un-finalized portion of the chain, quickly overwhelming Lighthouse nodes and causing OOM related crashes.
To remove these inefficient state lookups, we changed the way Lighthouse serve non-finalized blocks and blobs to peers. Instead of fetching the beacon state to calculate a range of block roots for a given range of slots, we use fork choice. Fork choice contains a DAG that stores slots and their associated block roots.
DAG: A directed acyclic graph. It's a type of data structure, consisting of vertices and edges that will never form a closed loop.
By accessing these non-finalized block roots via fork choice, we completely removed the need to perform any state lookups when serving block and blob data to peers. This reduced memory consumption and helped prevent Lighthouse from crashing.
During non-finality, inactivity leak penalities added roughly 70MB of new data to the Beacon State at each epoch boundary. By applying memory optimization techniques to the inactivity_scores field on the Beacon State, we were able to reduce memory usage down to 4MB.
We added more granular controls to the state cache, optimizing when to store fetched states in the cache and improving our state cache culling algorithm. Additionally, we reduced the default state cache size from 256 to 32 to further reduce memory usage. In the future, we're looking to add better heuristics to the state cache so that it can size itself dynamically based on its memory usage and other factors.
We'll Meet Again ♪♪
Don't know where, don't know when.
 It is highly recommended to listen to the song We'll Meet Again by Vera Lynn while reading this section.
It is highly recommended to listen to the song We'll Meet Again by Vera Lynn while reading this section.
It's unrealistic to assume we'll never see another non-finality incident again. As we continue making improvements to the protocol, we're bound to see bugs and other issues that affect the health of Ethereum testnets or Mainnet. Building safeguards, recovery mechanisms and optimizing clients to handle non-finality is critical to the long-term vision of Ethereum. As of late it seems we've chosen to focus on upgrades to the protocol over resiliency to worst-case scenarios. It's important to continue working on improvements to the protocol, especially as we continue to look towards cementing Ethereum as the World's Computer. But it's equally important to prepare for unexpected situations and catastrophic network conditions. So how do we prepare?
Non-Finality Testnets
Non-finality testnets are expensive and complicated to maintain. They're resource intensive from a computational perspective and require engineers to spend valuable time debugging and maintaining these networks. This type of work is extremely important, but hosting long-lived non-finality testnets is unrealistic. Instead we should launch short-lived non-finality networks on a semi-regular cadence to help stress-test clients under adverse network conditions. These non-finality networks can be scheduled quarterly, yearly or before scheduled upgrades to the network.
Non-Finality Interop Day
Ethereum's yearly interop event is a great way to get client teams all in one room to work on important upgrades to the protocol. At the last interop event in Kenya, client teams were able to get the first Pectra testnet finalizing in a single week. The productivity gains by having client teams all in one room is invaluable. If we were to dedicate a day or two of Interop to focusing on client resilience during adverse network conditions we may be able to make serious progress on building a more resilient Ethereum.
Client Team Prioritization
It's exciting to work on new cutting-edge features for the Ethereum protocol. It's fun, it's sexy and "scratches that itch" many engineers have for building cool new things. It's important to continue dedicating time to these endeavour's without ignoring critical work that can help save clients during unstable network conditions. I see many of Ethereum's best client engineers dedicating a significant portion of their time working on upgrades that might not even make it into the next scheduled Ethereum fork. We as a collective must re-prioritize and set aside a portion of our engineering hours towards work that can ensure Ethereum lasts for the next 100 years.
In Conclusion
The Lighthouse team is working on ensuring our software can handle non-finality and other adverse network conditions. Many of our optimizations during the Holesky incident have already made big improvements to stability and recoverability. These include:
- Reducing unnecessary state lookups when serving non-finalized data to peers.
- Adding better state cache culling logic, ensuring we keep good states in the cache.
- Introducing more granular controls on how/when we insert states into the state cache.
- Adding the ability to pseudo finalize the database so that Lighthouse can prune bad side-chains and reduce disk space usage.
- Include the ability to blacklist certain block roots so that nodes can ignore bad chains & peers while syncing.
- More syncing tools so node operators can keep their nodes on the canonical chain during adverse network conditions.
- Expand memory optimization techniques to additional Beacon State fields like
inactivity_scoreswhich can take up large amounts of memory during unhealthy network conditions.
We also have some exciting upcoming features that will make Lighthouse even more resilient
- Introduce a diff-based storage mechanism to the hot DB, AKA Hot Tree-States which will make disk usage a non-issue across both healthy and unhealthy network conditions.
- Add the ability for users to checkpoint sync to a non-finalized state. This allows node operators to socially coordinate around the right fork. This is a required feature if non-finality periods exceed 14 days.
- Better and more frequent use of testing tools that we can use to explore how Lighthouse behaves in adverse network conditions.
- Explore ways to prevent parallelized state cache misses and add better state cache heuristics.
- Improve our task scheduling mechanisms and add more granular controls so we can prioritize important tasks and de-prioritize non-important tasks in a dynamic manner, especially during periods of non-finality.
These are just some of the ways Lighthouse is looking to build a more robust Ethereum. If you have any questions, feedback or want to learn more please reach out to us on our discord.