

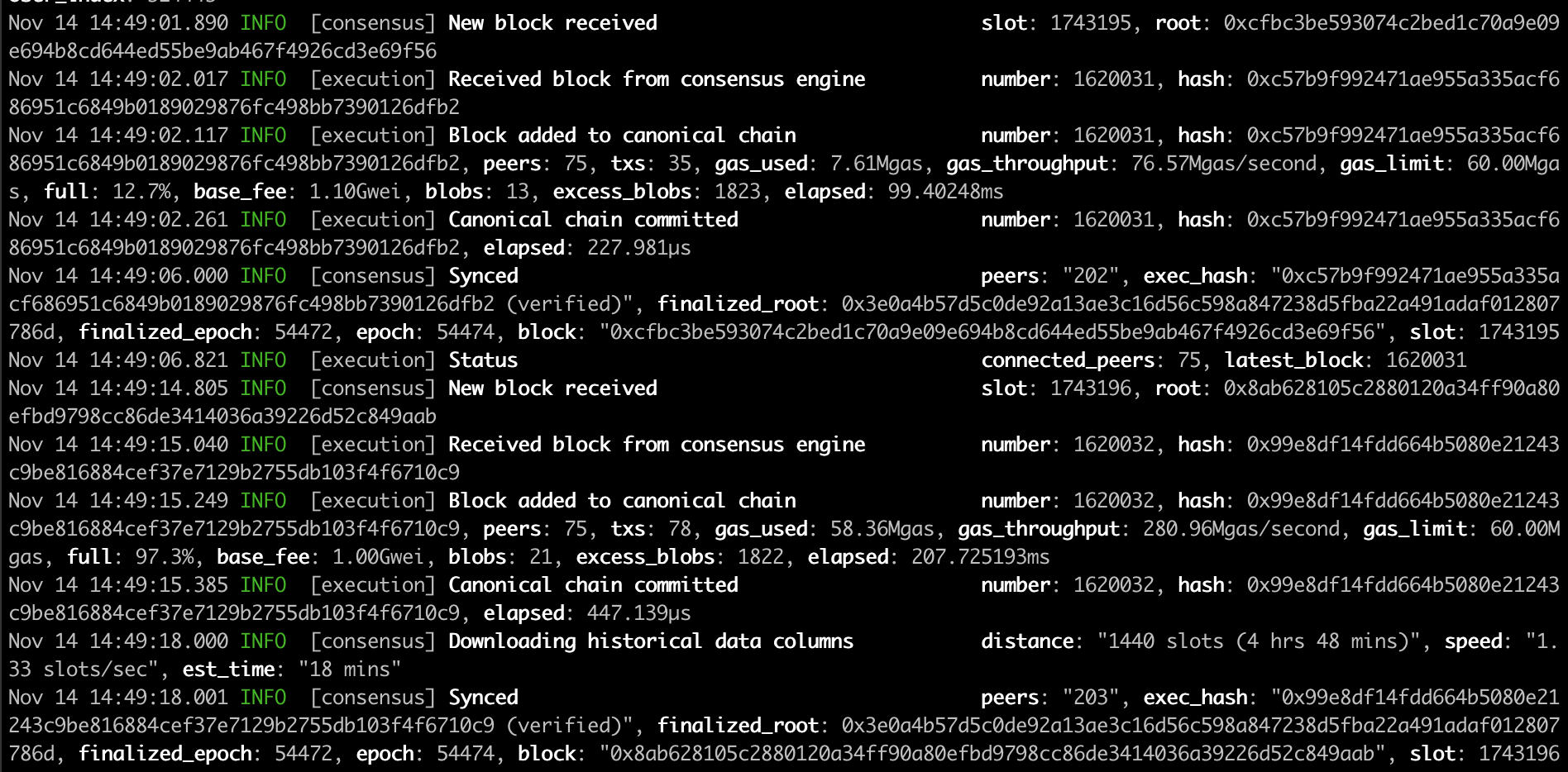
 Screenshot: "Fullhouse" syncing in progress.
Screenshot: "Fullhouse" syncing in progress.
This post documents a small experiment on a Lighthouse–Reth integration idea that came up a while ago but never really progressed. As gas limits and blob counts increase, more data flows between the consensus layer (CL) and execution layer (EL), and the current HTTP + JSON path may become increasingly expensive. SSZ support in the Engine API will help, but there are still some UX benefits worth exploring - so I did a short, time-boxed experiment with Claude to see what a single-binary setup might look like.
The idea is to have a single binary that runs both the consensus and execution layers - we call this "Fullhouse" - and running an Ethereum node could just be as simple as:
fullhouse --checkpoint-sync-url https://checkpoint.sigp.io
Background
CL and EL interact via the Engine API (HTTP)
┌─────────────┐ HTTP (JSON-RPC) ┌──────────────┐
│ Lighthouse │ ←─────────────────→ │ Reth |
│ (Consensus) │ │ (Execution) │
└─────────────┘ └──────────────┘
In-Process via Direct Calls or Channels
┌─────────────────────────────────────────────────┐
│ Single Lighthouse-Reth Binary │
│ ┌─────────────┐ ┌──────────────┐ │
│ │ Lighthouse │ ←──────→ │ Reth │ │
│ │ (Consensus) │ Direct │ (Execution) │ │
│ └─────────────┘ Calls └──────────────┘ │
└─────────────────────────────────────────────────┘
Possible benefits of CL + EL in a single binary:
- Better UX for regular users: Only one binary to download and run.
- Lower resource usage: Removes HTTP and JSON-serde overhead, which may become non-trivial as payload sizes and blob counts increase.
- Reduced latency: Direct function calls reduce latency in key paths like block production and block processing, which could help node and validator performance.
- End-to-end observability: Possibility to implement end-to-end client traces without having to implement distributed tracing.
The Proof of Concept
This section goes into the technical details of the prototype. If you don't care about the internals, feel free to skip to the next section.
This is a time-boxed POC, as I knew the rabbit hole could be very deep. Claude helped generate most of the initial code with the goal of having something working in a minimum amount of time, so the code is very rough, but the point is to see something working and learn about feasibility and the effort required.
I wanted to solve this with minimal changes because I believe this integration is not worth it if it adds too much maintenance or dependency overhead. So I considered just replacing HttpJsonRpc with RethEngineApi in the Lighthouse Engine struct. If I implement all the interfaces, this should just work.
pub struct Engine {
pub api: RethEngineApi,
pub json_api: HttpJsonRpc,
payload_id_cache: Mutex<LruCache<PayloadIdCacheKey, PayloadId>>,
state: RwLock<State>,
latest_forkchoice_state: RwLock<Option<ForkchoiceState>>,
executor: TaskExecutor,
}
Thanks to Reth's modular design, I was able to get Reth running within Lighthouse fairly quickly, and acquired a handle to the Reth ConsensusEngineHandle, which exposes the functions for the CL to drive the EL (forkchoice_updated and new_payload).
I realised the ConsensusEngineHandle wasn't sufficient because it doesn't expose the full set of engine methods - then I found the EngineApi struct, which was the correct interface to use and exposes all engine methods. Launching Reth and acquiring the EngineApi handle was reasonably straightforward:
debug!("Launching Reth node");
let engine_api = EngineApiExt::new(
BasicEngineApiBuilder::<EthereumEngineValidatorBuilder>::default(),
move |api| {
info!("Reth node started, extracting engine API handle");
let _ = handle_tx.send(Ok(api));
debug!("Extracted engine api handle");
},
);
let tasks = TaskManager::current();
let node_builder = NodeBuilder::new(node_config)
.with_database(db)
.with_launch_context(tasks.executor())
.with_types::<EthereumNode>()
.with_components(EthereumNode::components())
.with_add_ons(EthereumAddOns::default().with_engine_api(engine_api));
match node_builder.launch().await {
and boom -- we have working sync with CLs sending new blocks and fork choice updates to the EL! 🥳
The branch can be found here: https://github.com/jimmygchen/lighthouse/tree/lighthouse-reth
- Completed engine method integrations:
forkchoice_updatednew_payloadget_payloadget_blobs_v1get_blobs_v2- The remaining engine/RPC methods were not implemented, so the CL still uses HTTP for everything else.
- The only CLI flags passed to reth right now are
networkanddatadir. - One side note: converting Lighthouse types to/from Reth types currently requires manual field mapping. With JSON-RPC this wasn't needed because everything flowed through JSON. It's not a blocker, but it's some extra glue code that would need cleanup in a real implementation.
Testing and Metrics
The implementation is not optimised, but this post wouldn't be complete without some testing results!
I ran a comparison using separate Lighthouse & Reth binaries against Fullhouse on Hoodi testnet. Here's the command I used and the metrics below.
fullhouse bn --network hoodi \
--checkpoint-sync-url https://hoodi.beaconstate.info \
--http --metrics --telemetry-collector-url http://localhost:4317
fetch_and_process_engine_blobs
This span metric shows the p95 time to fetch blobs from the EL (engine_getBlobs method) and convert them into data columns. Fullhouse performs significantly better here.
| Lighthouse + Reth | Fullhouse |
|---|---|
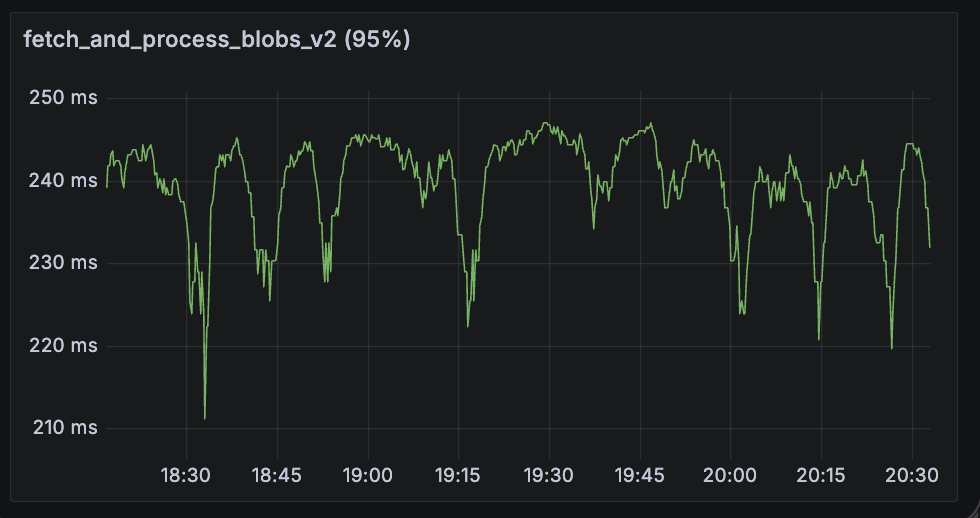 |
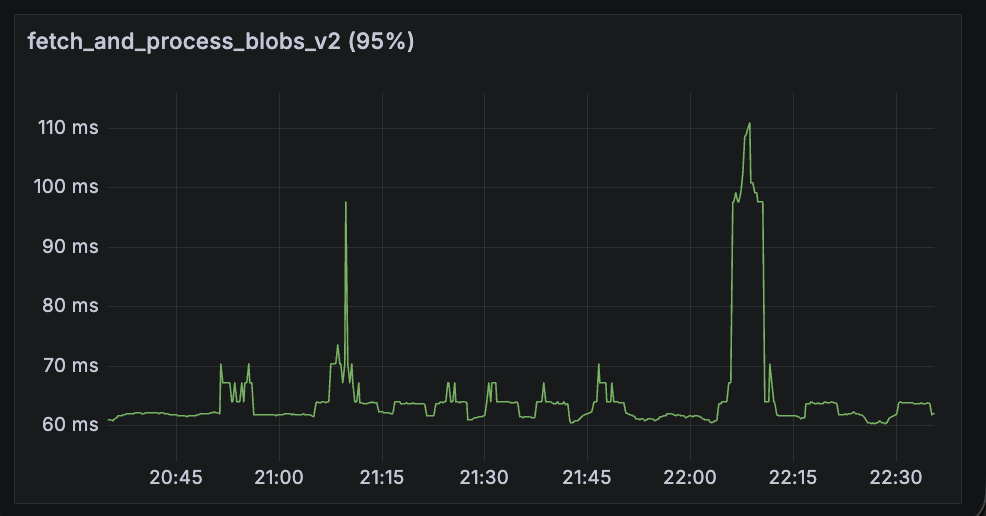 |
execution_layer_request_times
This metric shows the p95 duration of calls to the EL.
forkchoice_updated: both perform similarly here.new_payload: Fullhouse is slower here.
| Lighthouse + Reth | Fullhouse |
|---|---|
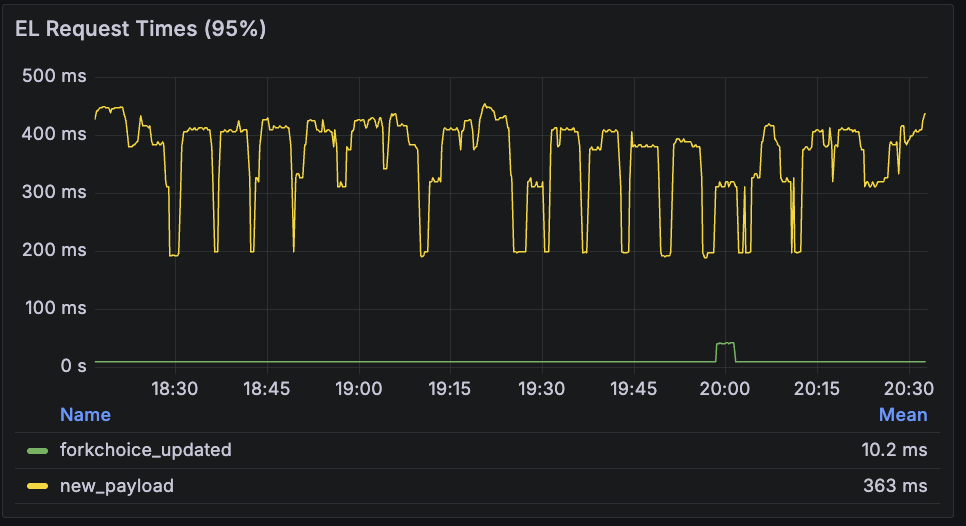 |
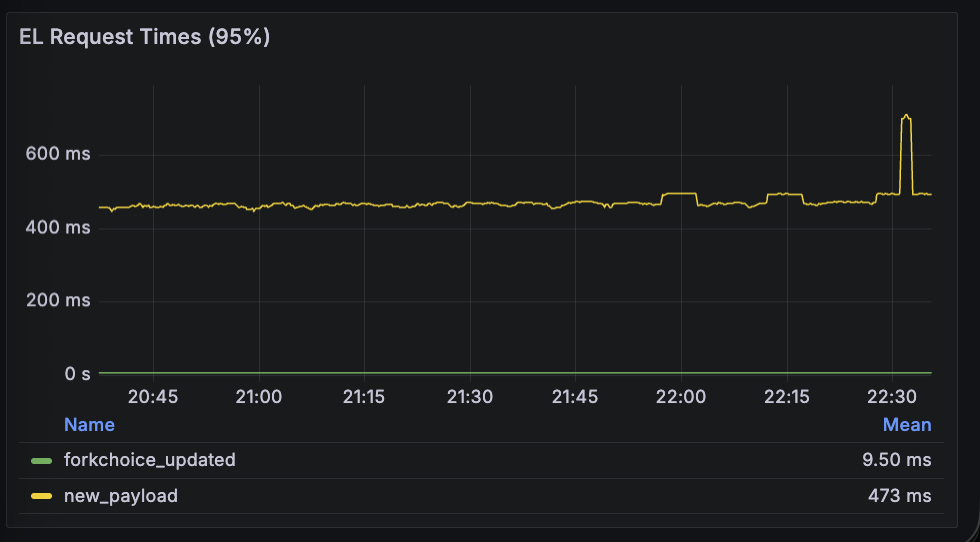 |
beacon_block_processing_seconds
This metric measures the p95 overall runtime of block processing, which includes executing the block and may include the time to import the block and data columns into the database. Fullhouse performs worse here as expected, as the bulk of time is spent on EL payload verification (new_payload method above).
| Lighthouse + Reth | Fullhouse |
|---|---|
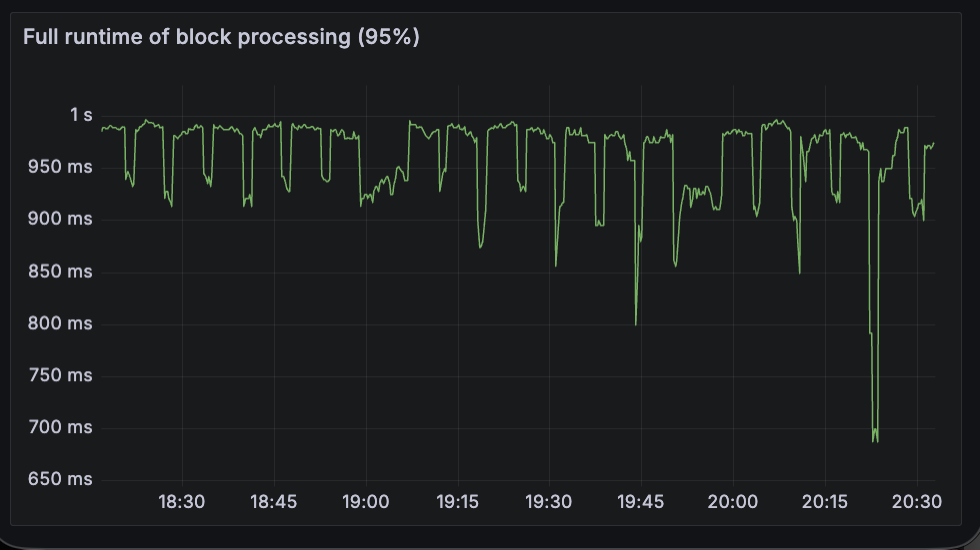 |
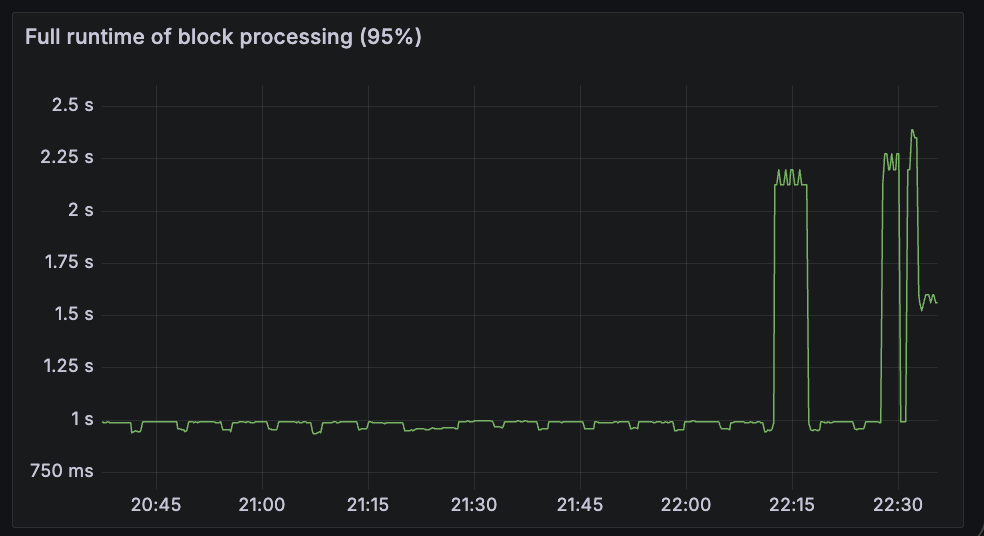 |
The faster get_blobs_v2 response time doesn't seem to help much here, because the critical path is the payload execution. See below trace for a block processing trace example:
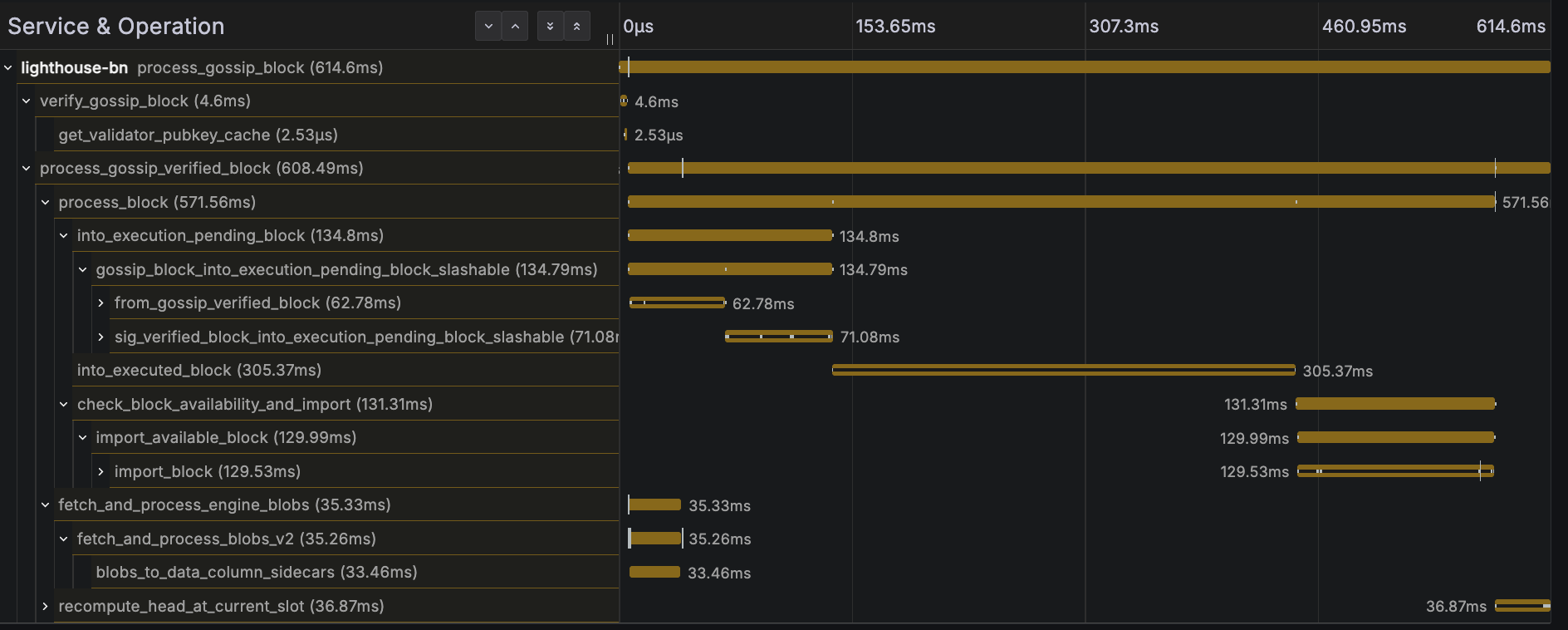
I mentioned potential observability benefits earlier, and the idea is that if we instrument the functions in the EL, we would be able to see all the key steps, easily identify what's taking the longest, and the code path taken, all in a single trace!
beacon_block_delay_attestable_slot_start
This metric shows the duration between the time that block became attestable and the start of the slot. The results are pretty similar here, average block-attestable time is around 2 seconds for both.
| Lighthouse + Reth | Fullhouse |
|---|---|
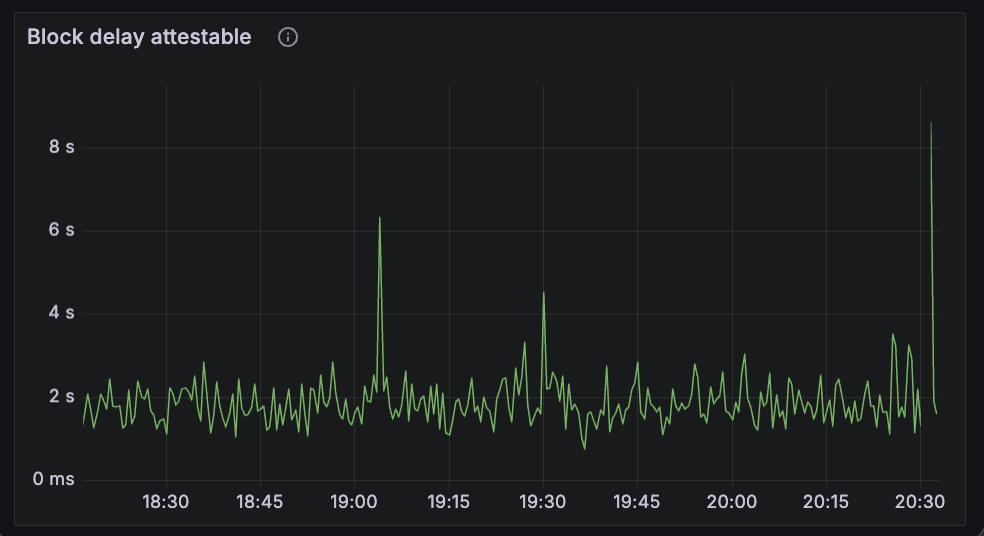 |
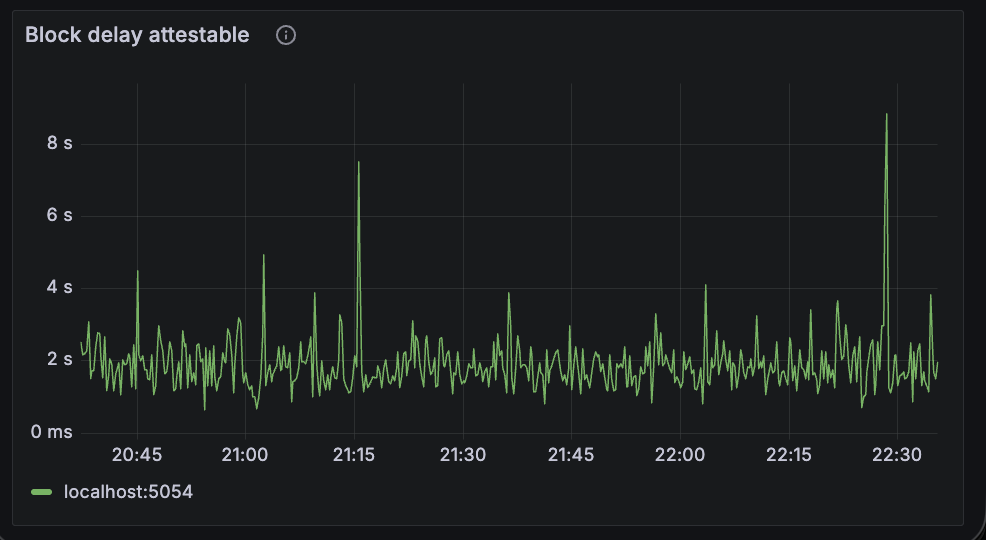 |
produce_block_v3
I ran a blockdreamer instance connected to the beacon node to trigger block production every slot. Fullhouse performs notably worse here. Unfortunately I didn't capture the right screenshots before shutting down the test instance, but during testing the p95 duration appeared to be roughly 2x slower.
Overall, the Fullhouse POC:
- Uses slightly more CPU overall, and memory usage is similar.
- Performs worse on CPU-intensive tasks like
new_payloadandget_payload. I suspect it's something to do with task scheduling or competing for the same Tokio and/or Rayon thread pools, when running Lighthouse and Reth inside a single process and Tokio runtime. This is most likely a solvable problem. - Performs better for large JSON responses like
get_blobs_v2.
Conclusion
It's pretty neat to be able to run a whole Ethereum node with a single command:
fullhouse bn --checkpoint-sync-url https://checkpoint.sigp.io
Note: the bn subcommand is only here because Lighthouse expects it - in a combined binary it's trivial to remove.
The performance results weren't the main focus, but it was quite satisfying to see it working! I've learned a lot from this POC in a short period, and it has been a fun experiment. The code was quickly put together (mostly by Claude) and very rough, but that was the goal - just a quick experiment to understand the challenges and viability. I did run into a few challenges and managed to solve some of them, and I think this idea is feasible and potentially worthwhile with the benefits mentioned earlier: better UX, lower resource overhead, improved performance and observability.
In terms of potential downsides:
- Ongoing maintenance effort required, e.g. dependency management, API updates
- Coordinating versions and releases
- Long compilation time
I've considered implementing this in a separate repo, however it was quite time-consuming to get the dependencies right (Claude struggled with that too), so I went with the quicker alternative to embed it in Lighthouse for the purpose of this experiment. This doesn't mean it's the right or preferred approach - bringing in a large codebase like Reth as a dependency isn't ideal - but it was just easier for Claude and me for this time-boxed POC. It would also slow down compilation times, so keeping it isolated behind a feature gate would be important in a real implementation.
Keen to hear what you think, feel free to reach out with any feedback or ideas. Thanks for reading!
Thanks to the Reth team - their modular design made this experiment smoother than it otherwise would have been, and to the Lighthouse team for reviewing this post and giving early feedback.