
We are pleased to announce a new graphical interface for Blockprint – our tool for tracking Ethereum's consensus client diversity. Since its inception 2 years ago, Blockprint has grown from a manually-updated spreadsheet into a small ecosystem of tools and infrastructure.
At the core of Blockprint is a machine-learning model which examines the structure of Ethereum blocks and determines the consensus clients that produced them. It fingerprints the consensus clients by looking for characteristic patterns in how they pack attestations. This fingerprinting allows us to estimate the client used by each validator on the network, and consequently the population-wide distribution. Owing to its importance for the security of the network, this client diversity metric is displayed front and centre in our new interface:
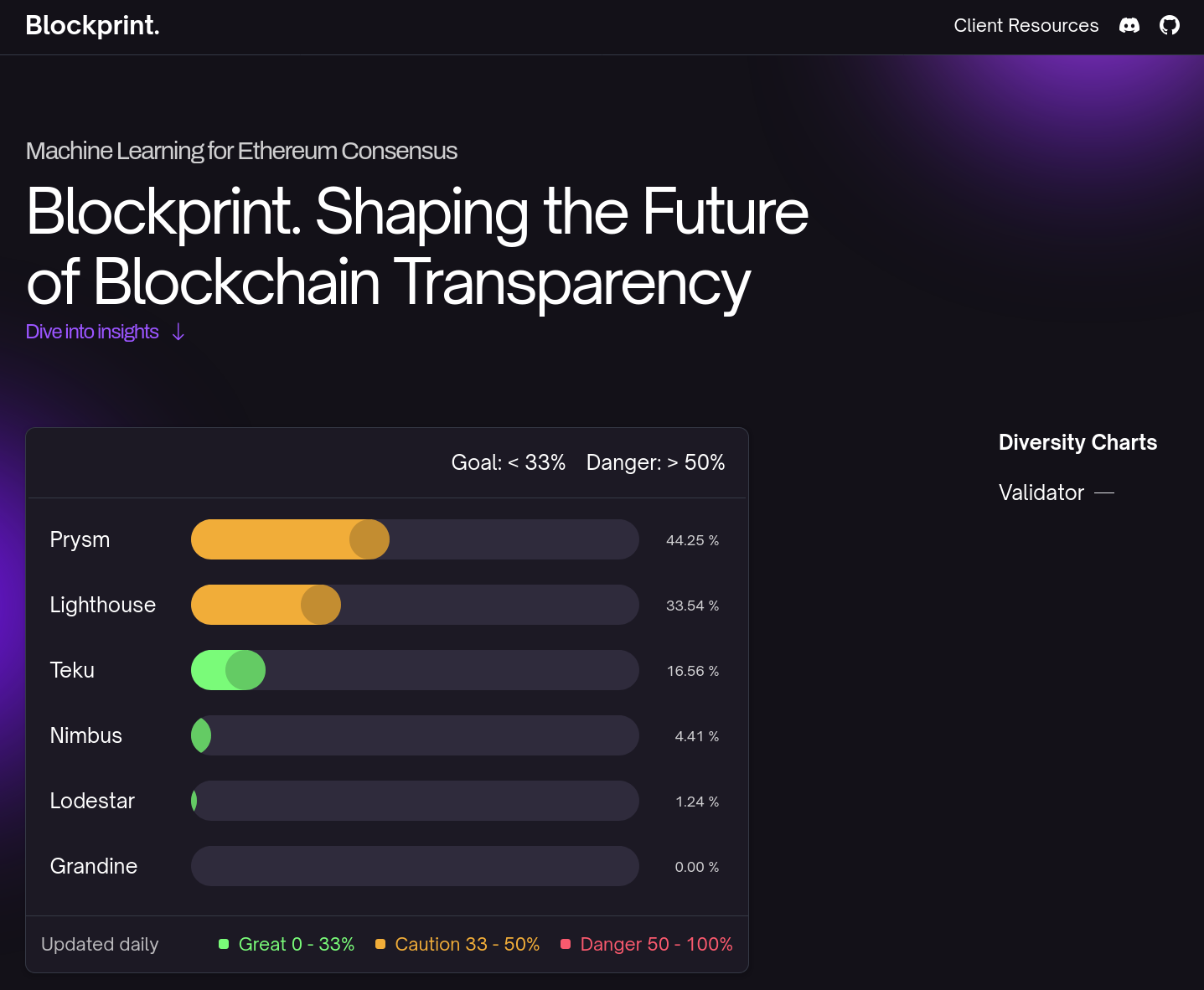
This chart is likely familiar to users of clientdiversity.org, which uses Blockprint data alongside other diversity estimates to provide a holistic picture of the network's health.
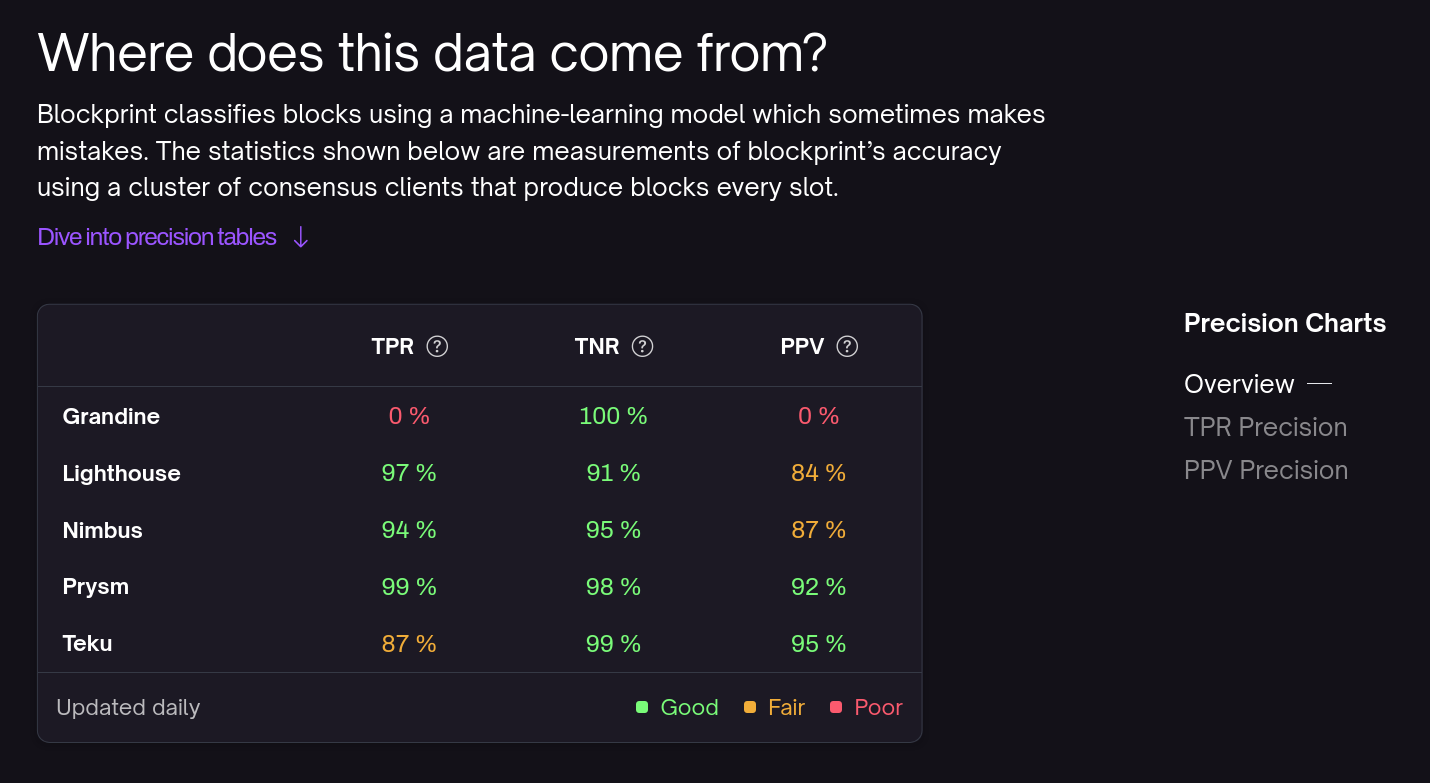
Although the diversity graph is nice, our primary motivation for developing the interface was to surface new data that previously had no visual representation, namely accuracy data. Like all machine-learning models, Blockprint is capable of making mistakes. It is therefore vital that we have a way of quantifying and tracking its accuracy over time. Our accuracy-tracking system uses a cluster of 12 consensus nodes of different types to continually measure Blockprint's performance. The consensus nodes produce blocks every slot (12 seconds) and feed these into Blockprint's model to see if they are correctly classified. From these measurements, we get counts of true positives and false positives which we use to compute statistical measures like the True Positive Rate (TPR) and the Positive Predictive Value (PPV). These values feature prominently in our new interface, with accompanying explanations:
What's Next?
Our goal is to continue refining Blockprint's accuracy with feedback from the accuracy tracker. We would also like to on-board more infrastructure providers who are interested in running their own Blockprint instances. We have recently added documentation on running Blockprint in production to aid in this. Our hope is that more running Blockprint instances and clusters of consensus nodes will produce more data to feed back into training updated models.
Links
- New user interface: https://blockprint.sigp.io/
- Blockprint repo: https://github.com/sigp/blockprint
Credits
The Blockprint UI was implemented by Mavrik based on the designs of Enialo. Devops assistance was provided by Anton, and design input and copy were provided by Tyler, Age and Michael.