

Prelude
This post is targeting technical readers that have a base-level understanding of Ethereum's consensus mechanism. With that said, you may have come here as a non-technical staker because you've noticed your node has been missing some attestations (and therefore is not achieving 100% performance on the network) and want to know how to rectify it. This post is aimed to provide useful information for both kinds of readers.
For the less technical readers, I'll cover what the possible problems are (in the Introduction) and explain easy ways that could help your node to improve efficiency (in the Common Issues and Potential Tuning Parameters section). The middle sections will aim to help you diagnose exactly what problems you are facing with your current node, and can probably be skipped for less-technical readers.
Introduction
The number of missed attestations is a metric that is being used quite commonly and is somewhat incorrectly being tied to the performance of a specific consensus client. This metric is useful as it is directly correlated with your validators profits, the less missed attestations a validator has, the more profitable it is, but also the healthier the network. It is in everyone's best interests to minimize the number of missed attestations. In fact, having a geographically diverse set of nodes on the network will actually help reduce the number of missed attestations and make it more robust and decentralised. Given an individual cannot change the general structure of the network, we're left with the question: how can we minimize missed attestations for our local node?
Before we dive into how, we must first understand what is going wrong when an individual validator misses an attestation. To do this, lets have a (very brief) detour into what an attestation actually is and how the voting process works.
Every epoch (6.4 minutes) every validator must "vote" exactly once on their current view of the chain. This includes three main values:
- Head - The block that we think is the current head of the chain
- Source - The most recent justified block
- Target - The first block of the epoch
Each validator decides on these values and puts the information into an object we call an Attestation. The validator client sends a signed version of this data structure to one (or many) beacon node(s). The beacon node then must find (or maintain) peers on a particular gossipsub topic (gossipsub is a publish/subscribe network protocol that disseminates messages to all nodes in the network) that this attestation must be sent on. Once it is sent, there are on average 16 aggregators (which are just other consensus nodes on the network) which group all the matching attestations into one grouped attestation, we call this an AggregateAttestation. There is one for each unique choice of the attestation variables mentioned above. The aggregator must then send these grouped attestations to a different gossipsub topic, we call this an aggregate_topic that all block proposers are listening on. Then, when a future block proposer goes to create a block, it selects the aggregates which maximize its profit. This can simply be thought of as collecting the attestations which align with the majority, meaning if a validator isn't voting with the majority, its attestation may be excluded (for more details on this process see our blog on Attestation Packing). If a validator's attestation gets included into a block in this process, the attestation has succeeded (provided the block doesn't get orphaned) and is therefore not classified as missed. If at any stage of this process something fails, the attestation is missed. The trick now is to identify at which stage this process is failing for any given node. The reason that the missed attestation metric being tied to a consensus client is misleading, is because this process involves many actors, often involving other clients and other nodes on the network. Here is a rough diagram of the process, highlighting the parts that your local node plays and parts that are outside of the control of your local node.

As you can see from this diagram, there is actually quite a few external actors to this process that contribute to missed attestations that is simply out of the control of your local node, regardless of your consensus client.
This is not to say that we may not be able to improve things :) (although we do a good job trying to set optimal defaults in Lighthouse).
Lets enumerate all the things than can contribute to a missed attestation, and then (using Lighthouse's metrics), try and diagnose what is the cause for your local node.
What Can Cause Missed Attestations
Late Blocks or Late Blobs
If you receive a block and its associated blobs late (later than 4 seconds into the slot) you cannot attest to it being the head. This is because at 4 seconds into the slot, you are required to make your attestation.
In these cases, your attestation may or may not be with the majority. If the block was fast enough to reach the majority of the network and it just arrived late to your local node, your attestation will be in the minority. If your attestation is in the minority, there is a good chance it will not get included into a block. Again we refer to the Attestation Packing blog post for further details here.
Note that these are largely not your local node's fault and can be caused by the following reasons:
- The block producer actually produced the block late - This has become a regular occurrence with block builders as the producer now has a number of extra steps in building a block. The block builders can now delay the production and subsequent propagation right up to the limit that some nodes on the network receive it too late. There is nothing your node can do to fix this case.
- The block propagation through the network was very slow - This also is a network effect that is largely unrelated to your node, however you can improve this via tweaking a lighthouse flag and we'll cover this later on.
- Your local network bandwidth is saturated - If your local network is saturated, you will queue messages. Lighthouse has made specific engineering choices to prioritise blocks as best as it can, but ultimately, if your network connection cannot handle the required bandwidth, you will see a large portion of seemingly late blocks/blobs because your network is lagging.
Block Processing Times
Once the block has been received from the network, Lighthouse needs to check its validity, applies fork-choice rules and ultimately adds it to its local database. This step requires CPU, RAM and disk-writes.
It can be the case that your node is using a slow SSD. QLC and DRAM-less SSDs are relatively slow and may use up considerable time to process blocks. To know if your SSD falls into this category, refer to the crowd source SSD list.
Alternatively, your node could be struggling with CPU resources. Both cases could lead to a delay in making a received block attestable, which can cause a minority head vote in the attestation and ultimately a non-inclusion in a future block.
Execution Layer Verification Times
In order for Lighthouse to be able to consider the block valid to vote on, it must check with the Execution Layer client if it is valid. This process can consume a bit of time and lead to a minority attestation by missing the current head block.
Validator Client Timing and Errors
This one is typically not a root cause of issues. The validator client must request from a beacon node the attestation to sign. It must sign it and return it. In most operating conditions this consumes very little to no time. However, if the validator client is at a distance from the beacon node and the connection is intermittent, it can happen that this delays the attestation which can cause non-inclusion. Additionally, if the validator client is on another computer and the clock isn't in sync, then the validator client may perform the attestation at the wrong time.
Publishing the Attestation on the Network
In order to publish the produced attestation on a network, each beacon node must
find a set of peers that are subscribed to a gossipsub topic that is associated
with the attestation we are publishing. There are 64 unique topics (attestation
subnets). Lighthouse
has a default peer count of 100 peers. It tries to maintain a set of 100 peers
such that at any given time we have a few peers that span every single possible
topic. Thus, when the node is required to publish an attestation, we have a few
peers to send it to.
It can happen that right at the time you need to send the attestation, the
peers on the topic we need immediately disconnect (for whatever reason). In this
case Lighthouse logs a publish warning stating InsufficientPeers. Lighthouse
tries to discover more peers for this topic and then republish your attestation
as soon as it can connect to a useful peer. If it fails, your attestation can
get missed or delayed.
Aggregator not Aggregating your Attestation
Once your node has published your attestation on the network, a pseudo-random node on the network must receive it and decide to aggregate your attestation. It is their job to do so, however it can be the case that your attestation gets missed or not aggregated properly (i.e it differs from the aggregator, or the aggregators didn't see the attestation in time). If this happens, your attestation will be missed and not included into any block. There is nothing you can do with your local node to prevent this.
Block Producer Not Including Your Attestation
Finally, once your attestation was made in a timely manner, aggregated, sent on the aggregate topic it is then picked up by a block producer. As the block space is limited, the block producer than has the difficult task to decide on which aggregates to include into the block and which to leave out, i.e, not all attestations can fit into a single block. If your attestation cannot fit into any block in an epoch, you will register a missed attestation. Again, I refer the interested reader to the Attestation Packing post to understand the details of why your attestation may not be included. As a brief summary, if your attestation is not in the majority (i.e. a late block leading to a missed head vote, or the attestation was published late), then it is harder for your attestation to be packed into a block. The majority "compress" (more technically aggregate) better so more can fit into a block which provides more profit to the block producer (so this is what they do).
If your attestation has the wrong target, its value is diminished and is much less profitable for the block proposer and so is therefore much more likely to be left out of a block. If your attestation has the wrong source, it cannot be included in the block and will count as a missed attestation. Luckily, its quite unlikely to have an incorrect source, as this is our view of the last justified slot (which if we are following the correct chain is almost always agreed upon).
As an overview, an attestation that matches with the majority on the head,target and the source has a much higher chance of being included than one that only matches on the target (and source) and this has a much high chance of being included than one that only matches on the source.
Your node cannot control what a block producer will pack into its block, the best we can do is try to get your local node to vote on what every other node on the network will vote on.
Orphaned Blocks
Finally, even if you made all the steps above and your attestation got included into a block, if that block then gets propagated late, it could be orphaned and essentially forked out of the chain, meaning so too are your attestations. If a block you were included in gets orphaned, you may see a missed attestation for that epoch. Lighthouse collects attestations from orphaned blocks and tries to pack them into blocks it produces later, so just because the block was orphaned doesn't mean so too will be your attestations, however they are now also competing with the block space of the subsequent blocks to be included and therefore have a higher chance of being left out.
Diagnosing Missed Attestations in Lighthouse
In this section, we will go through current tooling and some analysis to identify the root cause of missed attestations and comment on the most likely causes. We will go through a real-world example of a missed attestation on mainnet from a validator that I'm running at home (which is a poor Australian internet connection, so before we start I'm guessing its going to be network-related).
Lighthouse Logs
There are a few useful logs that Lighthouse emits that can help us diagnose missed attestations. For completeness, I'll list some helpful commands to see these logs, so that you can investigate some of the issues mentioned here yourself.
If you have set the --validator-monitor-auto flag on the Beacon node, it will
keep track of whether you have missed any attestations from your validator each
epoch.
You can access your beacon nodes log file from the default path of:
~/.lighthouse/mainnet/beacon/logs/beacon.log
To see if you've missed any attestations you can watch (tail -f) or search
(grep) through the logs for Previous epoch attestation. For example:
$ grep "Previous epoch attestation" beacon.log
Gives me the following:
Apr 22 00:16:20.257 INFO Previous epoch attestation(s) failed to match head, validators: ["xxxx", "xxxx"], epoch: 278438, service: val_mon, service: beacon, module: beacon_chain::validator_monitor:1050
Apr 22 00:16:20.257 INFO Previous epoch attestation(s) failed to match target, validators: ["xxxx"], epoch: 278438, service: val_mon, service: beacon, module: beacon_chain::validator_monitor:1059
Apr 22 00:16:20.257 INFO Previous epoch attestation(s) had sub-optimal inclusion delay, validators: ["xxxx"], epoch: 278438, service: val_mon, service: beacon, module: beacon_chain::validator_monitor:1068
From these logs we can see how each validator performs on each epoch. These logs tell us that our attestations missed the head vote, missed the target vote, and the "sub-optimal inclusion delay" tells us that our attestations were not included immediately in the next block, rather in later blocks. These logs are useful to track the attestation performance of your validators.
We can look at blocks coming in and attestations being sent out via:
$ grep -e "Slot timer" -e "Unaggregated attestation" -e "Sending pubsub" -e "New block received" ~/.lighthouse/mainnet/beacon/logs/beacon.log
Which for me results in the following (snippet):
Apr 22 00:42:53.001 DEBG Slot timer, sync_state: Synced, current_slot: 8910212, head_slot: 8910212, head_block: 0x3ef2…a2b8, finalized_epoch: 278442, finalized_root: 0xb4ac…e385, peers: 99, service: slot_notifier, module: client::notifier:180
Apr 22 00:43:00.317 INFO New block received, root: 0xa7a5f4be80bec9114c4fef16543d5bd9532dec9735c1d1e1dd44d7553ad11d19, slot: 8910213, module: network::network_beacon_processor::gossip_methods:916
Apr 22 00:43:03.001 INFO Unaggregated attestation, validator: X, src: api, slot: 8910213, epoch: 278444, delay_ms: 11, index: 43, head:0xa7a5f4be80bec9114c4fef16543d5bd9532dec9735c1d1e1dd44d7553ad11d19, service: val_mon, service: beacon, module: beacon_chain::validator_monitor:1263
Apr 22 00:43:03.045 DEBG Sending pubsub messages, topics: [Attestation(SubnetId(XX))], count: 1, service: network, module: network::service:656
Apr 22 00:43:05.001 DEBG Slot timer, sync_state: Synced, current_slot: 8910213, head_slot: 8910213, head_block: 0xa7a5…1d19, finalized_epoch: 278442, finalized_root: 0xb4ac…e385, peers: 96, service: slot_notifier, module: client::notifier:180
Apr 22 00:43:12.456 INFO New block received, root: 0x462f1dd0cfb3fa7f42c11d15c54cb0c053606bb8dc2457486442ad74fc0bb7e7, slot: 8910214, module: network::network_beacon_processor::gossip_methods:916
Apr 22 00:43:15.001 INFO Unaggregated attestation, validator: X, src: api, slot: 8910214, epoch: 278444, delay_ms: 11, index: 43, head: 0x462f1dd0cfb3fa7f42c11d15c54cb0c053606bb8dc2457486442ad74fc0bb7e7, service: val_mon, service: beacon, module: beacon_chain::validator_monitor:1263
Apr 22 00:43:15.104 DEBG Sending pubsub messages, topics: [Attestation(SubnetId(X))], count: 1, service: network, module: network::service:656
Apr 22 00:43:17.002 DEBG Slot timer, sync_state: Synced, current_slot: 8910214, head_slot: 8910214, head_block: 0x462f…b7e7, finalized_epoch: 278442, finalized_root: 0xb4ac…e385, peers: 96, service: slot_notifier, module: client::notifier:180
This shows the timing half-way through a slot ("Slot timer") then a block arriving ("New block received") for the following slot, then the beacon node producing and sending an attestation on the network ("Unaggregated attestation") and ("Sending pubsub messages").
You can see which validator is sending which messages via the validator client logs. The default location for these logs are:
~/.lighthouse/mainnet/validators/logs/validator.log
A few snippets of the info logs show the attestations at any given time:
Apr 22 00:49:15.104 INFO Successfully published attestations type: unaggregated, slot: 8910244, committee_index: XX, head_block: 0xd8d987ac0ba9a441b135d183913d7a69464481b44319ff35a1099b22f8530110, validator_indices: [XXXX], count: 1, service: attestation
Apr 22 00:49:15.105 INFO Successfully published attestations type: unaggregated, slot: 8910244, committee_index: XX, head_block: 0xd8d987ac0ba9a441b135d183913d7a69464481b44319ff35a1099b22f8530110, validator_indices: [XXXX], count: 1, service: attestation
From these logs we can match which validator is producing attestations on which slot. So if an attestation is missed, we can identify the exact validator and a slot.
Next, it is useful to see if a block arrived late for a specific slot. This could be the cause of the missed attestation. To identify these blocks, we search the lighthouse beacon logs to see:
$ grep -e "Delayed head" ~/.lighthouse/mainnet/beacon/logs/beacon.log
Which for me, results in:
Apr 22 00:50:51.376 DEBG Delayed head block, set_as_head_time_ms: 305, imported_time_ms: 106, attestable_delay_ms: 4037, available_delay_ms: 3963, execution_time_ms: 325, blob_delay_ms: 2775, observed_delay_ms: 3637, total_delay_ms: 4376, slot: 8910252, proposer_index: 255573, block_root: 0x05de8a29c9404ea5c2ae7914ddb81936bef8a85ced6455b88dd1014558e32c3f, service: beacon, module: beacon_chain::canonical_head:1503
Apr 22 00:51:27.017 DEBG Delayed head block, set_as_head_time_ms: 114, imported_time_ms: 35, attestable_delay_ms: 3892, available_delay_ms: 3867, execution_time_ms: 192, blob_delay_ms: 3867, observed_delay_ms: 3594, total_delay_ms: 4017, slot: 8910255, proposer_index: 1054833, block_root: 0x8991f3d82f94145a1153ca7677f4f72192d0f5fa0a387f34316c68c44082eb39, service: beacon, module: beacon_chain::canonical_head:1503
This gives me a list of blocks that arrived late, such that we did not have enough time to attest to the block. If one of these blocks coincides with the slot that your validator needed to attest to, it could be that your local node missed this block in its attestation and subsequently was a minority vote and didn't get included with the others in the next block. This log shows a number of delay metrics which we will look at in more detail in the next section.
If you want to see blocks and blobs that arrived late we can search for:
grep -e "Delayed head" -e "Gossip block arrived late" -e "Gossip blob arrived late" ~/.lighthouse/mainnet/beacon/logs/beacon.log
Which shows values such as:
Apr 22 00:36:39.056 DEBG Gossip blob arrived late, commitment: 0xb90d…cf12, delay: 4.050169655s, slot: 8910181, proposer_index: 1047912, block_root: 0xdb8fa58ceb049f2ec2ae65b5e6097f11d866c5a453f7303923143a0066e9f7ef, module: network::network_beacon_processor::gossip_methods:631
Apr 22 00:36:39.110 DEBG Gossip block arrived late, block_delay: 4.105806458s, slot: 8910181, proposer_index: 1047912, block_root: 0xdb8fa58ceb049f2ec2ae65b5e6097f11d866c5a453f7303923143a0066e9f7ef, module: network::network_beacon_processor::gossip_methods:906
Apr 22 00:36:39.903 DEBG Delayed head block, set_as_head_time_ms: 132, imported_time_ms: 38, attestable_delay_ms: 4759, available_delay_ms: 4731, execution_time_ms: 625, blob_delay_ms: 4056, observed_delay_ms: 4105, total_delay_ms: 4902, slot: 8910181, proposer_index: 1047912, block_root: 0xdb8fa58ceb049f2ec2ae65b5e6097f11d866c5a453f7303923143a0066e9f7ef, service: beacon, module: beacon_chain::canonical_head:1503
Here we can see that both the block and blob arrived late, potentially causing us to miss our head vote in the attestations.
We will leave the logging alone for now and move to more user friendly tools for analysing missed attestations.
Missed Attestation Dashboard
We've built a dashboard to help with the analysis. It's called
missed-attestations and can be found in our
lighthouse-metrics
dashboards page. (You will need the v5.2.0 of Lighthouse or later for this
dashboard to work.) You will need to have the --metrics flag on lighthouse
enabled and the lighthouse-metrics docker containers running and described on
that repository.
It looks like this:
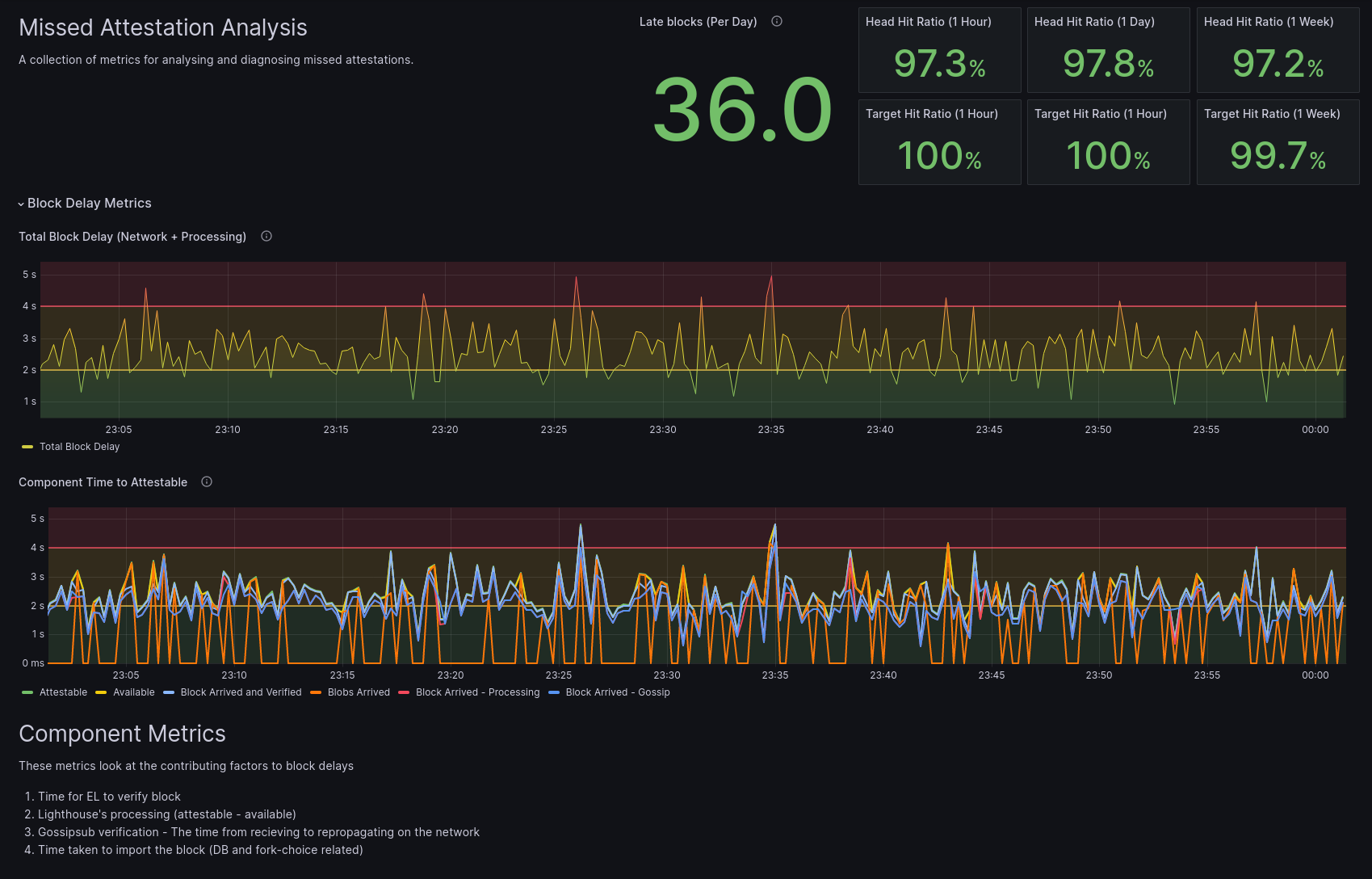
This provides an overview of metrics that are useful for analysing missed
attestations. The values on the top right of this dashboard give you statistics
over the last hour, day and week of expected performance given late blocks
arriving on the network. The first row show the head hit ratio. This is the
percentage of attestations that we expect to match on the head vote. Or
more specifically, the percentage of blocks that arrived on time for our
attestations to vote in time for.
The second row indicate the expected percentage of our local node to have their attestations match on the target vote. That is, that the first block of an epoch came on-time such that they could be included in the local nodes attestations. Having these percentages deviate from 100% generally indicates that blocks are arriving late and we could be missing them in our attestations. This can be a global network issue (out of your local nodes control) or an issue with your local internet connection. Let's look into the impact of late blocks in a bit more detail.
Late Blocks
As we have discussed, late blocks can be a source of why our attestations are not being included in blocks. Lets have a look at some metrics in detail.
The first graph shows a high-level overview of the timing of blocks your local beacon node is receiving.
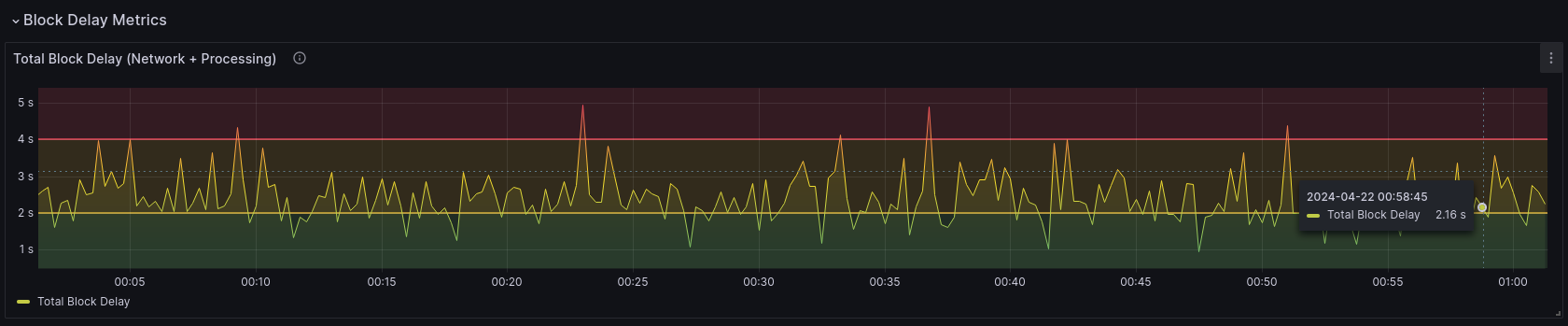
This gives the total time it takes for us to receive and import a block. It gives a high-level view of how late blocks and blobs are taking to arrive and process in your Lighthouse node. Ones that lie in the red region are generally arriving too late for us to attest to in a timely manner.
The second graph is a more useful one aimed directly at understanding the root cause of why the blocks are arriving late. It is measuring the time of all the components that occur in Lighthouse receiving a block and getting it ready to be attestable by the validator client. The largest time is the "attestable" time. This is the time it has taken since the start of the slot for the block to be attestable by a validator. If this value is in the red zone, then our validators could not attest to this block.
It shows the timing component for each block.
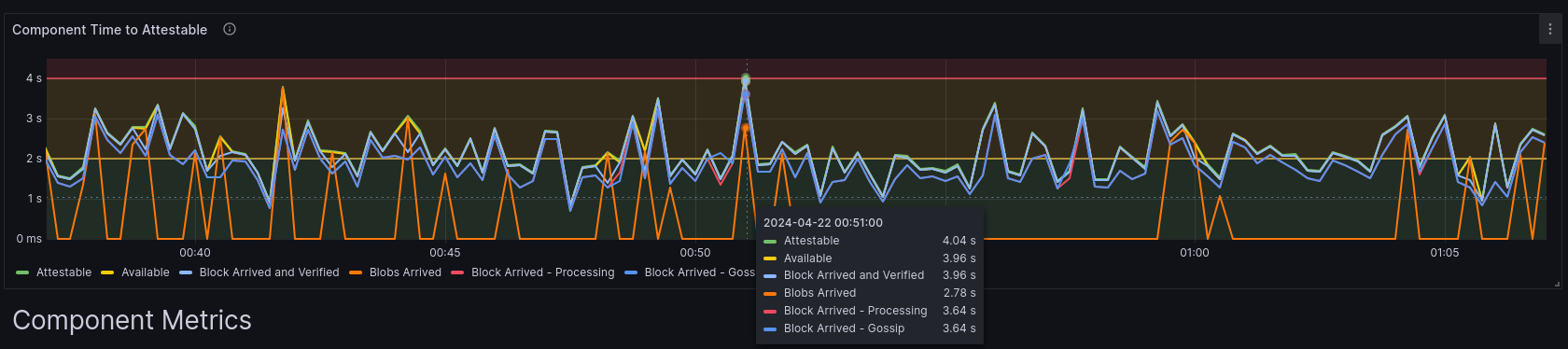
Here is a description for each component in this graph:
- Block Arrived - Gossip - This is the time it took for the block to arrive on our network over gossipsub.
- Blobs Arrived - This is the time taken for all required blobs to arrive on our network. In order for us to start processing a block, we require all blobs and the block to arrive. So you will notice that all other timings occur after either the blobs or the block arrived. Also note that some blocks do not have any blobs. In this case, the blob timing is set to 0 which you can see on the graph.
- Block Arrived - Processing - This is the time the block actually started being processed. Lighthouse has a queuing system. When the local node is over-loaded, blocks may wait a bit in order to be processed. If your node is not struggling with CPU resources, this time should be more or less the same as the Block Arrived - Gossip metric.
- Block Arrived and Verified - Once we receive a block from the network (regardless of the blobs) we need to verify it with the execution layer. This metric records the time it takes for us to get the block on the network and ask the EL if it is valid. It is (Block Arrived - Gossip + Execution Layer time). If your EL is slow (e.g., due to a slow SSD) or takes a lot of time to perform this request, your will notice a big difference here.
- Available - A block becomes available once we have received the block,
checked with the EL if it is valid and all of the blobs have arrived. This
metric should more or less coincide with
max(block_arrived_and_verified, blobs_arrived) - Attestable - This is the time the block has been processed and is available for validators to attest to it. If this occurs before 4s from the slot start time, a validator can use this block to attest.
In the example above, the block was attestable too late (4.04s). We can see that all our blobs arrived in time (2.78s) but the block arriving late on the network was the biggest problem (3.64s). Then, the execution layer took 320ms (3.96s - 3.64s, which is an alright value), leaving us to only have 40ms to process the block and make it ready to be attested to (attestable). In this case, this wasn't enough time, and thus if we were attesting on this slot, we likely would have missed the head vote (assuming it was not late for the rest of the network).
The dashboard shows some extra components broken up in their own graphs to easily identify potential issues with the block import times.

One slight area concern for my local node is the execution verification time. We can see there are regular spikes that range up into the 1.5s mark and is something worth investigating with my EL.
Insufficient Peers
Another source of missed attestations is the case that your local Lighthouse node does not have sufficient peers on a particular subnet that we need to attest on. In this case, Lighthouse will log a warning of the form:
WARN Could not publish message kind: beacon_attestation_43, error: InsufficientPeers, service: libp2p
You can search for these logs to find any occurrence of this kind of problem.
The dashboard is also set-up to identify these issues. The second section of the dashboard looks like this:
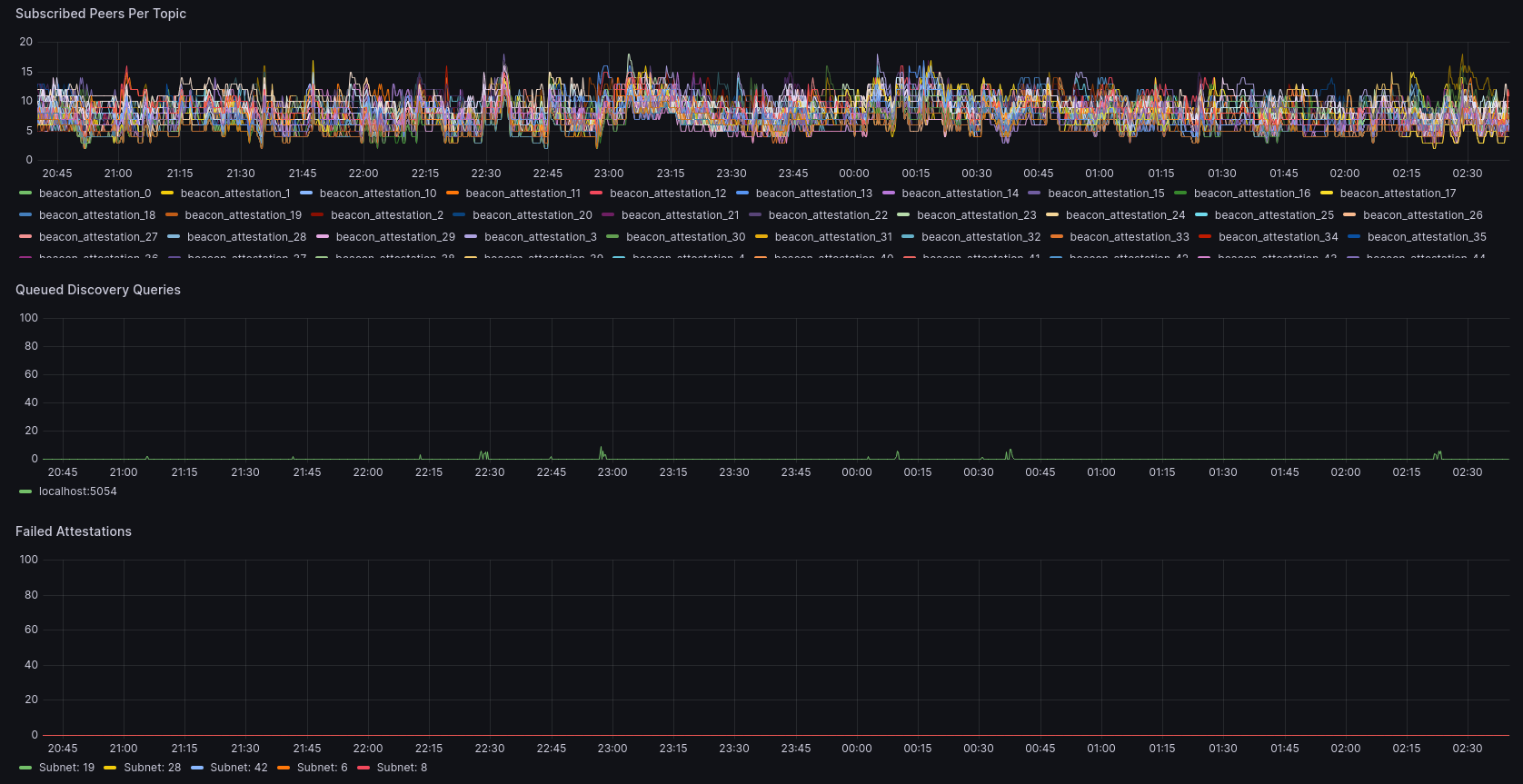
This section shows three graphs. The first is listing the peer count for all 64 attestation subnets and the 4 sync committee subnets. Lighthouse aims to keep a uniform distribution of these peers on all subnets. As long as you have at least one peer on all subnets, we should be able to always publish attestations to the network. In this example, my node seems to have between 5 and 15 peers on any given subnet. You might find a dip where a bunch of nodes disconnect and one of these subnets hits 0. This could be a cause for a missed attestation.
The second graph gives a list of queued discovery requests. Ideally this should be mostly 0 (as mine shows). In normal operation, Lighthouse shouldn't really require discovery queries as it should maintain a connection of useful peers without having to discover any. However, if a bunch of peers drop off a subnet, Lighthouse will start a bunch of discovery requests to try and search for peers on these subnets to connect to. This will be reflected in this graph. If your node is constantly doing discovery requests, it could be queuing them and important ones are delayed. This is a sign of poor network connectivity.
Finally, the last graph shows the number of times it failed to publish an attestation on a subnet. In the example, there are no failures, so the graph has no data to show. However, if there are missed attestations, you should notice spikes that will likely correspond with no peers on a given subnet and a few discovery searches trying to find those peers. If you see spikes in the bottom graph, then its very likely you are having issues finding and maintaining peers.
Real World Case-Study
Lets track down one of my missed attestations and see if we can identify the cause.
I received a tracking email, saying that validator X missed an attestation in
epoch 278438.
Lets look at our validator client logs for that epoch:
Apr 22 00:08:53.001 INFO All validators active slot: 8910042, epoch: 278438, total_validators: 64, active_validators: 64, current_epoch_proposers: 0, service: notifier
Apr 22 00:09:03.115 INFO Successfully published attestations type: unaggregated, slot: 8910043, committee_index: XX, head_block: 0xa4f55d872a5ef856469116245b81d7ad5b585b471a75f13707fa74fe787d9503, validator_indices: [xxxx], count: 1, service: attestation
Looks like it was the attestation on slot 8910043 that was missed. A quick
look for that slot on beaconcha.in shows
that the block root is 0x90af.. and we voted for its parent 0xa4f55... This
is indicative of a late block. Lets quickly search our logs:
$ cat beacon.log | grep "8910043" | grep -e "Delayed" -e "On-time"
This will search to see if the block was late or was on-time. The result:
Apr 22 00:09:03.344 DEBG Delayed head block, set_as_head_time_ms: 118, imported_time_ms: 41, attestable_delay_ms: 4209, available_delay_ms: 4184, execution_time_ms: 245, blob_delay_ms: 3985, observed_delay_ms: 3938, total_delay_ms: 4344, slot: 8910043, proposer_index: 726785, block_root: 0x90af45310b4c42692669acaab9dd94cada18ce6509e37f7232e826dbce2c7521, service: beacon, module: beacon_chain::canonical_head:1503
As we suspect, the block came to our node late. It became attestable after 4.2 seconds. The major delay was due to the network, as the block came in 3.9 seconds after the slot and the blobs arrived also 3.9 seconds after the slot. It took 245ms to verify the block at the EL, meaning it was available to process 4.18 seconds into the slot (past our 4s deadline). My validator therefore couldn't attest to this head block and was likely a minority in attestations when being accepted into a block.
If we look at the attestations on the following block (8910044) on
beaconcha.in, we can see that
the block was full (it had the maximum number of attestations 128).
Having a quick look through, it seems most of these aggregate attestations
voted on the late block 0x90af... Because my validator voted on 0xa4f55..
my attestation seems to be in the minority and was not selected to be included
in the block.
As I was in the minority, and this block arrived marginally late, it implies the rest of the network saw this block on time. This typically means, one of two things.
1) My geographical location (Australia) has some inherent latency, which means most of the network saw the block, but me being alone on my island in the southern hemisphere saw it late and couldn't attest to it. As the majority of the network are not in Australia, then I am left as the minority voter and any other Australian's that saw this block marginally late too are likely to have their attestations left out also. It should be noted, that this block could have been published late, but early enough that it reaches the majority of the network, it was just that the extra latency to reach Australia that made this just too late for my node to attest to it.
2) My internet connection is poor. This happens more than I'd like. My home
network can get saturated from misc family members downloading content such
that my node takes longer to download the block than it should. This coupled
with the fact that Australia has some of the worst internet connections on the
planet, some of my late blocks are actually due to my local internet connection
(and I can't just blame geographic latency). One way to help identify this
scenario, is to look at the general participation of the network on the block.
In this example, slot 8910043 had
29222 (unique validator) votes on it. There should be around
total_validator_count/32 votes on a block, which at the time or writing is
about 31k. So 29222 votes indicates around a 94% participation rate. You can
also view the proceeding blocks sync committee participation which is ~90% in
this case. This is relatively low, indicating that this block was late for ~10% of
validators. If this rate is high, around 98%+ it is likely that it is just your
local node that is seeing it late, rather than it being published late on the
network.
Lets also have a look at this block from our dashboard. By comparing the UTC time at which this block appeared: Apr 22 00:09:03, with our dashboard, we see:
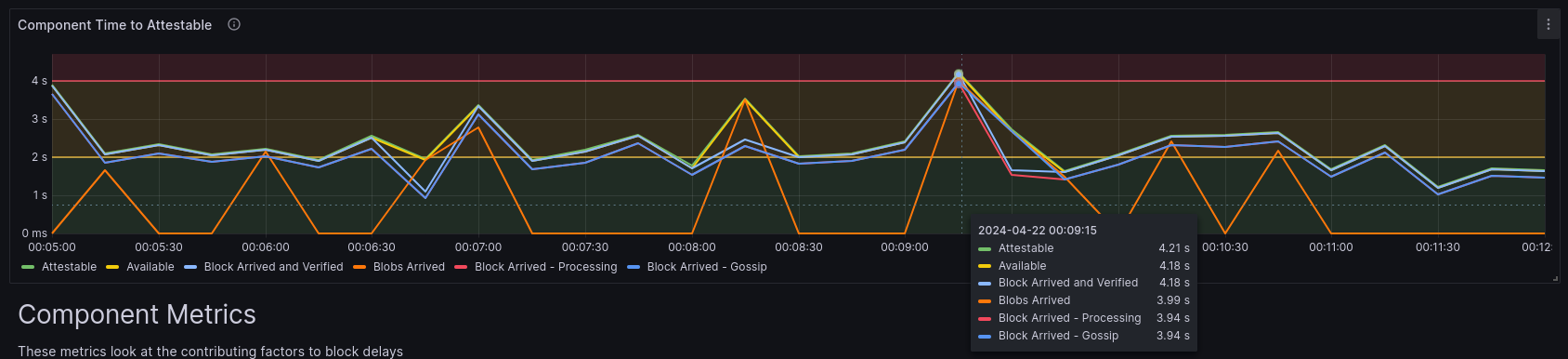
This graph shows the block that arrived late. The primary cause of this block arriving late was that it took too long for all the blobs to arrive (3.99s). The blobs arriving late was entirely network related. The subnet stability graphs show no errors, and most of the network saw this block in time. It was therefore the fact that we attested to the wrong head that made this attestation less favourable for inclusion into any blocks this epoch.
Common Issues and Potential Tuning Parameters
Here we list some of the most likely reasons for missed attestations and potential things a user can do to improve them.
Late Blocks
As we have seen, late blocks are a primary cause for missed or sub-optimal inclusion attestations. As we have discussed, there are multiple factors that could contribute to late blocks, including:
- The block builder/proposer produces/sends them late
- The geographic distance of your node has increased latency relative to the majority of nodes on the network
- Your local network's bandwidth could be saturated
If you are running your node on a cloud provider, although this is bad for diversity, locating it near Europe or the US may reduce the number of missed attestations. The better solution is to get the majority of the nodes to be geographically diverse such that average latencies are felt from all nodes and late blocks will simply be orphaned by the network.
If bandwidth is not of any concern to you, Lighthouse has a CLI parameter which
can increase your node's bandwidth use in order to speed up network propagation
(i.e improve the time to get blocks/blobs). The parameter is --network-load.
Setting this to a value of 5 will increase Lighthouse's bandwidth, and should
improve block times and therefore reduce the missed attestation rate (provided
your network bandwidth can handle the load).
We are also working on protocol improvements to improve the efficiency of the network and Lighthouse will be experimenting with some new gossipsub designs in the next few releases to improve the propagation speeds without the added bandwidth costs.
Insufficent Peers on Subnets
This seems to be another common issue amongst users. As explained above,
Lighthouse attempts to maintain a uniform distribution of peers across all
subnets. The algorithm takes a while to sift through peers until it finds a
good stable set. Therefore, when you initially start the client, up to around 30 mins
after startup, Lighthouse's peer set may be unstable and you may see missed
attestations with the InsufficientPeers warning. Letting the client run for a
bit should give you a stable set of peers.
The algorithm heavily relies on an inbound flow of peers. This means we are expecting a lot of new peers to be connecting to us. In order for this to happen you need to make sure you have correctly forwarded your UDP (discovery) and TCP (libp2p) ports. See the Advanced Networking section of our Lighthouse book for further details.
If you find yourself continually having this problem, increasing the
--target-peers flag (which has a default of 100) to a higher number like 150
or 200, should improve this (as you will have more peers to balance across
subnets). However, it will come again with a cost of increased bandwidth.
Others
The above are the two primary causes for missed attestations that we have seen.
Another possible cause of missed attestation is due to the clock not being
synced. For this, you can check with timedatectl and ensure that the field
System clock synchronized is enabled (set to yes). From the metrics
dashboard, you may notice excessive time delays in processing blocks (CPU
limited) or Execution verification (EL running slow, potentially due to a slow
SSD). In these cases you may need to increase the resources of your machine, or
if it is not obvious the cause for the resources consumption reach out to one
of us on our Discord.
The Future
We are aware of some inadequacies of the Ethereum consensus network. We are working on protocol improvements which will be released in the next few versions of Lighthouse. This should hopefully improve network propagation, however we can't fix block producers/proposers from publishing blocks late. The best we can do is to get the network to orphan blocks that the whole network see as being too late.
In future hard forks, there may be changes that provide extra room in blocks for attestations that do not align with the majority and therefore allow for greater inclusion and resilience against nodes witnessing late blocks. These changes should improve the overall participation rate and should reduce the number of missed attestations on the network.
In the meantime, I hope the information here is useful and that readers are now able to self-diagnose the root cause of their missed attestations.